
- kubernetes 资源对象
- k8s 基础应用
- Pod 生命周期
- Pod 资源限制
- deployment
- daemonset
- job、cronjob
- service
- ingress
- configmap
- secret
- statefulset
- 授权与认证(RBAC)
- 准入控制(ResoucesQuta、LimitRange)
1.0 k8s 基础应用
1.1 deploy
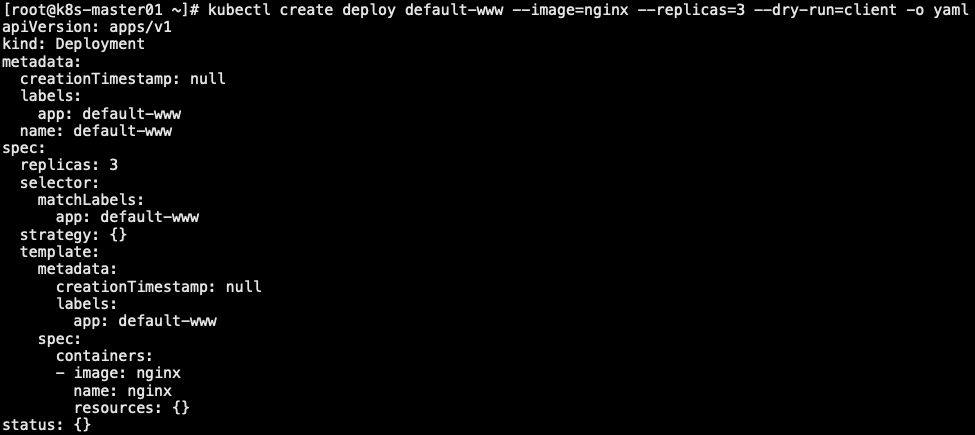
1 | // 空跑 deploy def-www 资源来获取模版 |
1.2 pod 重启策略
- restartPolicy(重启策略):
- Always:当容器终止退出后,总是重启容器,默认策略
- OnFailure:当容器异常退出(退出状态码非0)时,才重启容器
- Never:当容器终止退出,从不重启容器
1.3 pod 镜像拉取策略
- imagePullPolicy: 容器的镜像拉取策略:
- IfNotPresent: 本地有镜像则使用本地镜像,本地不存在则拉取镜像 (默认)
- Always: 每次都会尝试拉取镜像
- Never: 永不拉取,如果镜像已经在本地,kubelet 会尝试使用镜像启动容器;否则,会启动失败
1 | ... |
1.4 获取私有仓库镜像
1.4.1 创建 secret 认证
- ImagePullSecrets 拉取私有仓库中的镜像
1 | // 将 harbor 的认证信息保存到 k8s secret 资源中 |

1.4.2 yaml 部署验证
1 | ... |
1.5 传递环境变量
- 使用 env 控制容器环境变量
- mysql docker 镜像下载及变量等信息
1 | # cat mysql-demo-env.yaml |
1.6 自定义容器命令与参数
- command: 为容器指定启动命令,会覆盖容器启动的默认命令,不指定则默认容器的启动命令
- args: 为命令提供选项或参数
1 | # cat pod-busybox-command.yaml |
1 | // 重点在于颜色 args |
2.0 Pod 生命周期
2.1 初始化容器
- init container 是用来做初始化工作的容器,可以有一个或多个,如果多个按照定义的顺序依次执行,只有所有的执行完成后,主容器才启动,由于一个 pod 里的存储卷是共享的,所以 init container 里产生的数据可以被主容器使用到,但它仅仅是在启动时,在主容器启动前执行,做初始化工作。如果 pod 的 init 容器失败,kubernetes 会不断重启该 pod,直到 init 容器成功为止。如果 pod 对应的 restartPolicy 值为 Never, kubernetes 不会重新启动 pod。
- 应用场景:
- app 容器依赖 mysql 的数据交互,所以可以启动一个初始化容器检查 mysql 服务是否正常,如果正常则启动主容器
- 在启动主容器之前,使用初始化容器对系统内核参数进行调优,然后共享给主容器使用
- 获取集群成员节点地址,为主容器生成对应配置信息,这样主容器启动后,可以通过配置信息加入集群环境
2.1.1 场景1-端口检查
- 编写 yaml,使用初始化容器对 mysql 端口进行检查,如果存活则运行 pod,否则就一直重启尝试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# cat init-check-mysql.yaml
apiVersion: v1
kind: Pod
metadata:
name: init-check-mysql
spec:
imagePullSecrets:
- name: harbor-registry-auth
initContainers:
- name: check-mysql
image: harbor.inadm.com/inadm_kubernetes/tools:latest
command: ["sh", "-c", "nc -z MYSQL_POD_IP 3306"]
securityContext: # 特权模式运行容器,否则无法修改内核参数
privileged: true
containers:
- name: app-mysql
image: nginx
ports:
- containerPort: 80
// 这里的 "MYSQL_POD_IP" 是使用的 1.4 mysql-demo-env 容器 IP 地址,主要是为了演示初始化容器场景的实现
# kubectl apply -f init-check-mysql.yaml
2.1.2 场景2-内核参数优化
- 使用初始化容器对内核参数进行优化
1 | # cat init-sysctl-nginx.yaml |
2.2 钩子函数
- 钩子函数用来监听容器生命周期的特定事件,并在事件发生时执行已注册的回调函数
- 当一个容器启动后,kubernetes 将立即执行 postStart 事件关联的动作
- 在容器被终结之前,kubernetes 将立即执行 preStop 事件关联的动作
- 两种钩子
- postStart: 容器创建后立即执行,由于是异步执行,它无法保证在容器之前运行。如果失败,容器会杀死,并根据 RestartPolicy 决定是否重启
- preStop: 在容器终止前执行。用于: 释放占用的资源、清理注册过的信息、优雅的关闭进程。在其完成之前会阻塞删除容器的操作,默认等待时间为 30s,可以通过 terminationGracePeriodSeconds 宽限时间
2.2.1 钩子示例
1 | // 通过 postStart 设定端口重定向,将请求本机的 8080 调度到本机 80 端口 |
1 | // runner 主要用来编译打包提高 CI 效率。启动后会注册到 gitlab 上,后续不需要可以删除 Pod,然后清理注册信息 |
2.2.2 钩子场景1
- postStart 命令在容器的 /usr/share/nginx/html/index.html 自定义一段内容
- preStop 负责优雅地终止 nginx 服务
- terminationGracePeriodSeconds 宽限期,如果超过宽限期 pod 还没有终止,则会由 SIGKLL 强制关闭信号介入
1 | # cat 1-pod-postStart.yaml |

2.2.3 钩子场景2
- postStart 命令负责将默认页面拷贝至 /usr/local/tomcat/webapps
- preStop 负责给容器发送 SIGTERM 信号,从而优雅地终止 tomcat 服务
- terminationGracePeriodSeconds 宽限期,如果超过宽限期 pod 还没有终止,则会由 SIGKILL 强制关闭信号介入
1 | # cat 2-pod-postStart.yaml |

2.3 检测探针
- 为何需要探针: 当容器进程运行时如出现异常退出,k8s 则会认为容器发生故障,会尝试进行重启解决该问题。但有些情况是发生了故障,但进程没有退出。比如访问 web 服务时出现 500 错误,可能是系统超载,也可能资源死锁,但 nginx 进程并没有异常退出,在这种情况下重启容器是最佳方法,如何来实现检测
- kubernetes 使用探针(probe)方式来保障容器正常运行,实现零宕机。它通过 kubelet 定期对容器进行健康检查 (exec 、tpc、http),当探针检测到容器状态异常时,会通过重启策略来进行重启或重建完成修复。修复后继续进行探针检测,以确保容器稳定运行
2.3.1 探针检测类型
- 针对运行中的容器,kubelet 可以选择一下三种探针来探测容器的状态
- startupProbe 启动探针: 用于检测容器中的应用是否已经正常启动。如果使用了启动探针,则所有其它探针都会被禁用,需要等待启动探针检测成功之后才可以执行。如果启动探针探测失败,则 kubelet 会将容器杀死,而容器以其重启策略进行重启。如果容器没有提供启动探测,则默认状态为 Success
- livenessProbe 存活探针: 用于检测容器是否存活,如果存活探测检测失败, kubelet 会杀死容器,然后根据容器重启策略,决定是否重启该容器。如果容器不提供存活探针,则默认状态为 Success
- readinessProbe 就绪探针: 指容器是否准备好接收网络请求,如果就绪探测失败,则将容器设定为未就绪状态,然后将其从负载均衡列表移除,这样就不会有请求会调度到该 Pod 上。如果容器不提供就绪探针,则默认状态为 Success
2.3.2 探针检查机制
- 使用探针来检查容器 [只能任选其一]
- exec: 在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功
- httpGet: 对指定的 IP、端口,执行 HTTP 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的
- tcpSocket: 对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的
- 每次探测都获得以下三种结果之一
- Success:容器通过诊断
- Failure:容器未通过诊断,可能会触发重启操作
- Unknown:诊断失败,因此不会采取任何行动
2.3.3 startupProbe
- 有时会有一些应用在启动时需要较长的初始化时间。若要不影响对死锁做出快速响应的探测,设置存活探测参数是要技巧的。技巧就是使用相同的命令来设置启动探测,针对 HTTP 或 TCP 检测,可以通过将 failureThreshold * periodSeconds 参数设置为足够长的时间来应对最糟糕情况下的启动时间
2.3.3.1 exec
1 | # kubectl create ns inadm |
2.3.3.2 httpGet
1 | # cat pod-startprobe-httpget.yaml |
2.3.3.3 tcpSocket
1 | # cat pod-startupprobe-tcp.yaml |
2.3.4 livenessProbe
2.3.4.1 exec
1 | # cat pod-livenessprobe-exe.yaml |

2.3.4.1 httpGet
1 | # cat pod-livenessprobe-httpget.yaml |

2.3.4.2 tcpSocket
1 | # cat pod-livenessprobe-tcp.yaml |
2.3.5 readinessProbe
- 有些程序启动需要加载配置或数据,甚至有些程序需要运行预热的过程,需要一定时间。所以需要避免 Pod 启动成功后立即让其处理客户端请求,而应该让其初始化完成后转为就绪状态,在对外提供服务。此类应用就需要使用 readinessProbe 探针
2.3.5.1 exec
1 | # cat pod-readinessprobe-exec.yaml |
2.3.5.2 httpGet
1 | // 需要有 svc 服务配合,此处简略不加入 svc 验证 |
2.3.5.3 tcpSocket
1 | # cat pod-readinessprobe-tcp.yaml |
3.0 Pod 资源限制
kubernetes 通过 Requests 和 Limits 字段来实现对 Pod 的资源限制
- Requests: 启动 Pod 时申请分配的资源大小 (Pod在调度时requests比较重要)
- Limits: 限制 Pod 运行时最大可用的资源大小 (Pod在运行时limits比较重要)
CPU 限制单位
- 1 核 CPU 等于 1000 毫核,当定义容器为 0.5 时,所能用到的 CPU 资源是 1 核心 CPU 的一半,对于 CPU 资源单位,表达式 0.1 等价于表达式 100m,可以看做 100 millicpu
1
21C = 1000 millicpu (1 coer = 1000m)
0.5C = 500 millicpu (0.5 coer = 500m)
- 1 核 CPU 等于 1000 毫核,当定义容器为 0.5 时,所能用到的 CPU 资源是 1 核心 CPU 的一半,对于 CPU 资源单位,表达式 0.1 等价于表达式 100m,可以看做 100 millicpu
内存分配单位: 内存的基本单位是字节数(Bytes),也可以加上国际单位,十进制的 E、P、T、G、M、K、m,或二进的 Ei、Pi、Ti、Gi、Mi、Ki
1
21MB = 1000KB = 1000000 Bytes
1Mi = 1024KB = 1048576 btyes
3.1 cpu 资源限制
3.1.1 cpu 请求和限制
- 创建一个 Pod,容器将请求 0.5 个 CPU,最多限制使用 1 个 CPU
1 | # cat cpu-requests-limits.yaml |

3.1.2 超过节点 cpu 请求
- 创建一个pod,设置该pod中容器的请求为100核,这个值会大于集群中的任何一个节点
1 | # cat pod-requests-limints.yaml |

3.1.2 不指定cpu limits
- 如果没有为容器指定cpu限制,那么容器在可以使用的cpu资源是没有上限。因而可以使用所在节点上所有的可用cpu资源,这样会造成一个pod占用大量cpu,可能会导致其它pod的正常运行,从而造成业务的不稳定
- kubernetes中,可以通过 LimitRange 自动为容器设定,所使用的CPU资源和内存资源最大最小值
3.2 内存资源限制
3.2.1 mem 请求和限制
- 创建一个Pod,容器将会请求 100MiB 内存,并且内存会被限制在 200MiB 以内
1 | # cat pod-mem-requests-limits.yaml |

3.2.2 超过容器mem限制的应用
- 当节点有足够的内存时,容器可以使用其请求的内存。但是,容器不允许使用超过其限制的内存。如果容器的内存超过其限制,该容器会成为被终止的候选容器。如果容器继续消耗超过其限制的内存,则终止容器。如果终止的容器可以被重启,则 kubelet 会重新启动它
1 | // 创建一个pod,其拥有一个容器,该容器的内存请求为 100MiB,内存限制为200MiB,尝试分配超出其限制的内存 |

3.2.3 超过节点mem分配
- pod 的调度基于请求。只有当节点拥有足够满足Pod内存请求的内存时,才会将pod调度至节点上运行
1 | // 创建一个pod,其拥有一个请求 100GiB内存的容器,这应该超过了集群中任何一台节点所拥有的内存 |

3.2.4 未指定内存限制
- 如果没有为容器指定内存限制,容器可无限制地使用其所在节点的所有可用内存,进而可能导致该节点调用 OOM Killer。此外,如果发生 OOM Kill,没有配置资源限制的容器将被杀掉的可行性更大
- 不用担心,在 kubernetes中,可以通过 LimitRange 自动为其容器设定,所使用的内存资源最大最小值
3.3 Qos 服务质量
Qos [服务质量等级] or [服务质量保证],是作用在pod上的一个配置,当kubernetes创建一个pod时,它就会给这个pod分配一个Qos等级
在k8s环境中,k8s允许节点的pod过载使用资源,这意味着节点无法同时满足所有pod以过载方式运行。因此在内存资源紧缺情况下,k8s需要借助pod对象的服务质量和优先级等完成判定,进而挑选对应的pod杀死。k8s根据pod的requests和limits属性,把pod对象归类为 BestEffort、BurStable、Guaranteed
Qos 类别:
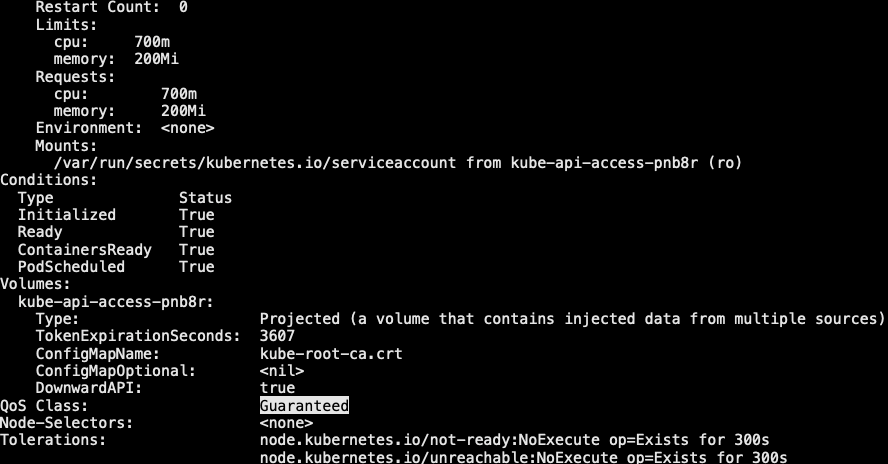
- Guaranteed: pod对象为每个容器都设置了cpu资源需求和资源限制,且两者的值相同;还同时为每个容器设置了内存需求和内存限制,并且两者的值相同。这类pod对象具有最高级别服务质量
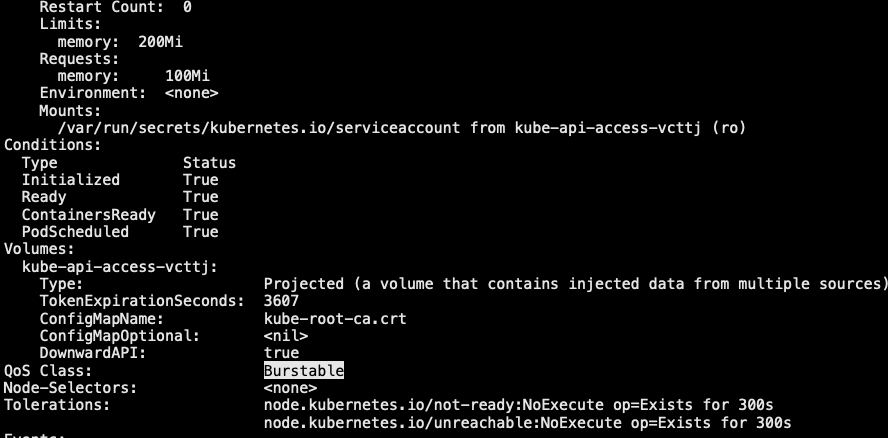
- Burstable: 至少有一个容器设置了cpu或者内存资源requests属性,但不满足Guaranteed,这类pod具有中级服务质量
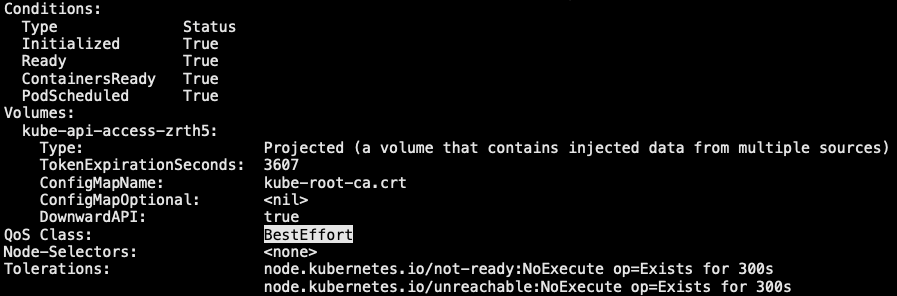
- BestEffort: 没有为任何容器设置requests和limits属性,这类pod对象服务质量是最低级别
当k8s集群内存资源紧缺,优先杀死 BestEffort 类别的容器,因为系统不为该资源提供任何服务保证,但此类资源最大的好处就是能够尽可能使用资源
当k8s集群内存资源紧缺,优先杀死 BestEffort 类别的容器,因为系统不为该资源提供任何服务保证,但此类资源最大的好处就是能够尽可能使用资源
对于 Guaranteed 类别容器拥有最高优先级,他们不会被杀死,除非其它内存资源需求超限,或者 OOM 时没有其它更低优先级的 pod 对象存在,才会干掉 Guaranteed 类容器
3.3.1 创建Guaranteed的pod
1 | // pod中的每个容器都必须指定内存请求和内存限制,且pod中每个容器内存请求必须等于内存限制 |
3.3.2 创建Burstables的pod
1 | // 如果满足下面条件,将会指定pod的Qos类型为Burstable: |
3.3.2 创建BestEffort的pod
1 | // 对于Qos类为 BestEffort 的 pod,pod 中的容器必须没有设置内存和cpu限制或请求 |
3.3.3 创建多个容器pod
1 | // 创建一个pod,一个容器指定了内存请求 200MiB。另外一个容器没有指定任何请求和限制。此pod满足burstable Qos类的标准。但它不满足 Guaranteed Qos 类标准,因为它的一个容器没有内存请求 |

3.4 downward api
- 什么是 DownwardAPI: DownwardAPI 可以让容器获取pod的相关元数据信息,比如pod名称、pod_ip、pod的资源限制等,获取后通过env、volume的方式将相关的环境信息注入到容器中,从而让容器通过这些信息,来设定容器的运行特性
- 例如: nginx 进程根据节点的cpu核心数量自动设定要启动的worker进程数
- 例如: jvm虚拟根据pod的内存资源限制,来设定对应容器的堆内存大小
- 例如: 获取pod名称,以pod名称注册到某个服务,当pod结束后,调用prestop清理对应名称的注册信息
3.4.1 可注入元数据信息
- 使用 pod.spec.containers.env.valueFrom.fieldRef 可以注入的字段有:
- metadata.name: Pod 对象的名称
- metadata.namespace: Pod 对象隶属于名称空间
- metadata.uid: Pod 对象的 UID
- metadata.labels “KEY”: 获取 Label 指定 KEY 对应的值
- metadata.annotations “KEY”: 获取 Annotations 对应 KEY 的值
- status.podIP: Pod 对象的IP地址
- status.hostIP: 节点IP
- status.nodeName: 节点名称
- spec.serviceAcconuntName: Pod 对象使用的 ServiceAccount 资源名称
- 使用 pod.spec.containers.env.valueFrom.resourceFieldRef 可以注入的字段有:
- requests.cpu
- requests.memory
- limits.cpu
- limits.memory
3.4.2 环境变量注入元数据
1 | // 创建Pod容器,将Pod相关环境变量注入到容器中,比如(pod名称、命名空间、标签、以及cpu、内存的请求和限制) |
3.4.3 存储卷注入元数据
1 | # cat pod-downward-api.yaml |

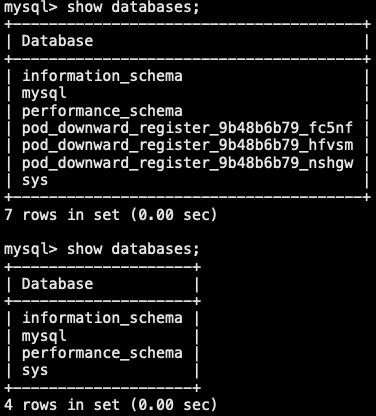
3.4.4 为注册服务注入pod名称
- 使用 DownwardAPI 实现注册与卸载
1 | # cat pod-register.yaml |
3.4.5 为Tomcat注入对内存限制
- 默认Tomcat应用会使用Pod所在的物理节点内存,初始堆内存为1/64,最大堆内存为1/4
- 1、运行一个默认的Tomcat,检查初始jvm堆内存大小
1 | # cat pod-tomcat-1.yaml |

2.对Tomcat设定资源限制,看看这个资源限制对Tomcat分配内存有没有影响
1 | # cat pod-tomcat-2.yaml |

- 3.手动为Tomcat指定堆内存,500M,对pod限制100M
1 | # cat pod-tomcat-3.yaml |

- 4.将 request limits 值,传递给 jvm 内存设定
1 | # cat pod-tomcat-4.yaml |

4.0 deployment
4.1 replicaset
- ReplicaSet 控制器包含了3个基本组成部分
- selector 标签选择器: 匹配并关联 Pod 对象,并加入控制器的管理中
- replicas 期望的副本数: 期望在集群中所运行的 Pod 对象数量
- template Pod 模板: 定义 Pod 规范,相当于把一个 Pod 的描述以模板形式嵌入到了 ReplicaSet
1 | // RS 控制器更新缺点:更新时会统一 kill 掉 Pod 然后统一拉起 |
4.2 deploy
- Deployment 控制器包含 3 个基本组成部分
- selector 标签选择器: 匹配并关联 Pod 对象,并加入控制器的管理中
- replicas 期望的副本数: 期望在集群中所运行的 Pod 对象数量
- template Pod 模板: 定义 Pod 规范,相当于把一个 Pod 的描述以模板形式嵌入到了 ReplicaSet
1 | # cat deploy-demo.yaml |

- 检查集群 Deployment
- NAME:列出了集群中的 Deployment 的名称
- READY:显示应用程序的可用副本数。显示的模式是 “就绪个数”/“期望个数”
- UP-TO-DATE:显示为了达到期望状态已经更新的副本数
- AVAILABLE:显示应用程序可供用户使用的副本数
- AGE:显示应用程序运行的时间
4.3 svc
1 | # cat deploy-svc.yaml |
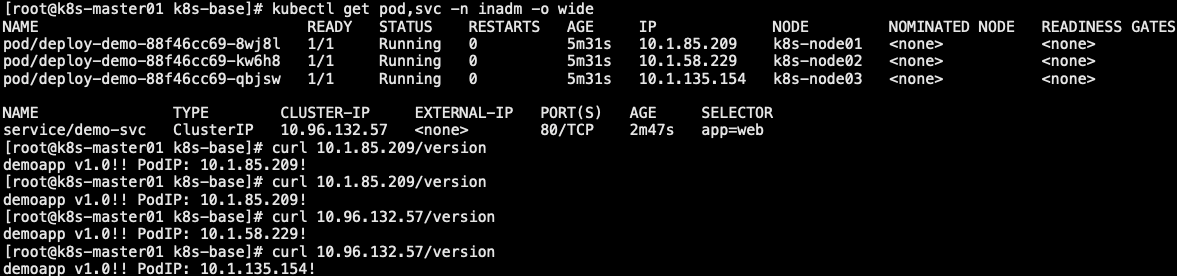
4.4 hpa
- 什么是 HPA:k8s 实现 Pod 的扩容缩容需要通过手动来实现,但线上业务情况复杂,依赖于纯手动方式不太现实。所以希望系统能自动感知 Pod 的压力来完成扩缩容,比如: 当 Pod 的 CPU 达到 50% 则扩容,当 Pod 的 CPU 低于 50% 自动缩容。为此 k8s 提供了一个资源对象 HPA(horizontal-pod-autoscaler),专用来实现 Pod 的水平自动扩缩容。HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量
- 自动扩缩容算法(基于 metricserver):
- 当前指标:当前 Pod 已经达到百分之多少的压力
- 期望指标:当前 Pod 达到期望的指标百分比时就要进行扩容
- 例如:当前副本数 1,当前指标值 200%,期望指标值 50%,则副本数为 1 * (200% / 50%) = 4
1 | # cat hpa-deploy.yaml |

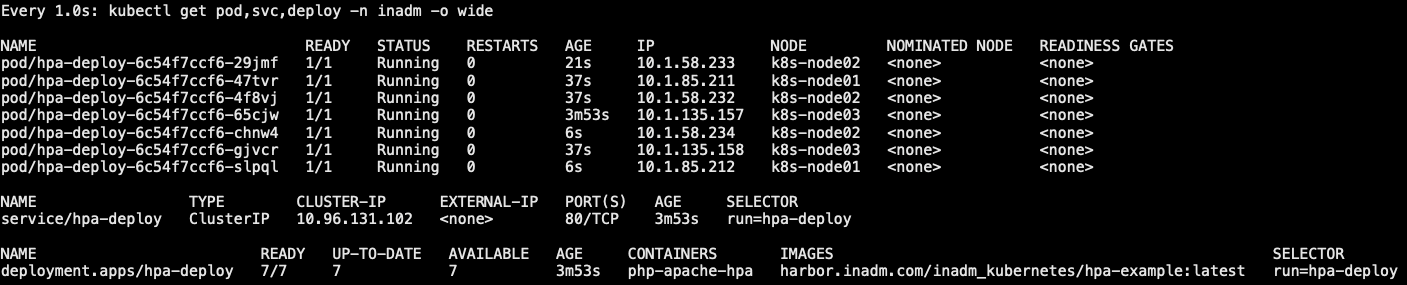
4.5 recreate 重建策略
- 什么是 Recreate:当更新策略设定为 Recreate,在更新镜像时,它会先杀死正在运行的 Pod,等彻底杀死后,重新创建的 RS,然后启动对应的 Pod,在更新过程中,会造成服务一段时间停止提供服务
- 1.同时杀死所有旧版 Pod,此时 Pod 无法正常对外提供服务
- 2.创建新的 RS,启动新的 Pod
- 3.等待 Pod就绪,对外提供服务
1 | # cat deploy-recreate.yaml |



4.6 rollingupdate
- 什么是滚动更新:一次仅更新一批 Pod,当更新的 Pod 就绪后,在更新另一批,知道全部更新完成为止;该策略实现了不间断服务的目标,在更新过程中可能会出现不同的应用版本并存且同时提供服务的情况
- 1.创建新的 ReplicaSet,然后根据新的镜像运行新的 Pod
- 2.删除旧 Pod,启动新 Pod,新 Pod 就绪后,继续删除旧 Pod,启动新 Pod
- 3.持续第二步过程,直到所有 Pod 都被更新成功
1 | # cat deploy-rollingupdate.yaml |

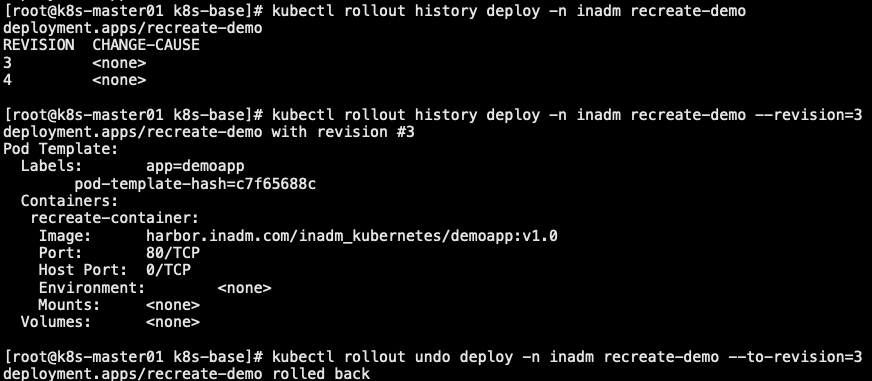
4.7 rollout
- 可以通过修改 revisionHistoryLimit 调整保留的数量,默认 10 条
1 | # kubectl rollout history deploy -n inadm recreate-demo # 查看历史版本 |

4.8 deploy 更新策略
- Deplolyment 会在 .spec.strategy.type=RollingUpdate 时,采取滚动更新方式更新 Pod。可以指定 maxUnavailable 和 maxSurge 来控制滚动更新过程
- maxSurge 最大可用 Pod
- 用来指定可以创建超出期望 Pod 个数的 Pod 数量。可以是数字,可以是百分比。此字段默认值 25%
- 例如:当此值为 20% 时,启动滚动更新后,会立即对新的 ReplicaSet 扩容,同时保证新旧 Pod 的总数不超过所需 Pod 总数的 120%。一旦旧 Pod 被杀死,新的 ReplicaSet 可以进一步扩容,同时确保更新期间任何时候运行的 Pod 总数最多为所需 Pod 总数的 120%。计算公式: 10+(10*20%)=12
- maxUnavailable 最大可用 Pod
- 用来指定更新过程中不可用的 Pod 的个数上线
- 例如:当此值设置为 20% 时,滚动更新开始时会立即将旧 ReplicaSet 缩容到期望 Pod 个数的 70%。新 Pod 准备就绪后,继续缩容旧的 ReplicaSet,然后对新 ReplicaSet 扩容,确保更新期间可用的 Pod 总数任何时候都是所需的 Pod 个数的 70%。计算公式: 10-(10*20%)=8
- maxSurge 和 maxUnavailable 两个属性协同工作,可以组合定义出 3 种不同策略完成多批次应用更新
- 先增新,后减旧:将 maxSurge 设置为 30%,将 maxUnavailable 的值设为 0
- 先减旧,后增新:将 maxUnavailable 设置为 30%,将 maxSurge 值设置为 0
- 同时增减,将 maxSurge 和 maxUnavailable 分别设置为 20%,期望是 12 Pod,至少就绪 8 个 Pod
- maxSurge 最大可用 Pod
4.8.1 maxSurge
- 指定升级期间存在的总 Pod 对象数量最多可超出期望值的个数,可以是 0,也可以是整数,也可以是一个百分比
- 例如:副本数为 10,maxSurge 属性为 2,则表示 Pod 对象总数不能超过 12 个。计算公式: 10+(10*20%)=12
1 | # cat pod-maxsurge.yaml |

4.8.2 maxUnavailable
1 | # cat deploy-maxUnavailable.yaml |

4.8.3 surge 和 unavailable
- 同时设定 maxsurge 和 maxunavailable
1 | # cat deploy-max.yaml |

4.8.4 paused 暂停更新
- 例如在滚动更新时,发现异常,可以进行更新暂停操作
1 | # cat deploy-paused.yaml |
4.8.5 minreadyseconds
- deploy 支持使用 spec.minReadySeconds 字段来控制滚动更新的速度,默认值为 0,表示新建的 Pod 对象一旦 “就绪” 将立即被视作可用,随后即可开始下一轮更新过程。如果设定了 spec.minReadySeconds: 5 及表示新建的 Pod 对象至少要成功运行多久才会被视作可用,及就绪之后还要等待指定的 5s 才能开始下一批次的更新。在一个批次内新建的所有 Pod 就绪后再转为可用状态前,更新操作会被阻塞,并且任何一个 Pod 就绪探测失败,都会导致滚动更新被终止。因此,为 minreadySeconds 设定一个合理的值,不仅能够减缓更新的速度,还能够让 deploy 提前发现一部分程序因为 bug 导致的升级故障
1 | # cat deploy-minready.yaml |
4.8.6 revisionhistorylimit
- deploy 保留一部分更新历史中旧版本的 ReplicaSet 对象,当我们执行回滚操作的时候,就直接使用旧版本的 ReplicaSet,在 deploy 资源保存历史版本数量有 spec.revisionHistoryLimit 属性进行定义
1 | # cat deploy-revi.yaml |
4.8.7 progressdeadlineSeconds
- 滚动更新故障超时时长,默认 600s,k8s 在升级过程中有可能由于各种原因升级卡主(这时还没明确的升级失败),比如在拉取被墙的镜像,权限不够等错误。如果配置 progressDeadlineSeconds,当达到时间还卡着,则会上报这个异常情况,这时 deploy 状态就被标记为 False,并且注明原因。但是它并不会阻止 deploy 继续进行卡住后面的升级操作
1 | # cat deploy-progress.yaml |
4.9 deploy 灰度发布
- 灰度发布(又名金丝雀发布)是指黑与白之间,能够平滑过渡的一种发布方式
4.9.1 deploy v1.0
1 | # cat deploy-demo-a.yaml |
4.9.2 deploy v1.1
1 | # cat deploy-demo-b.yaml |
4.9.3 实现方式
- 先增加 v1.1 版本的 replicas 副本数量,然后减少 v1.0 版本 replicas 的副本数量,逐步进行切换
- 其中 deploy 中 selector 有2个标签,svc 中有一个标签
- 最后在清除下线的 deploy 时,注意不要删除 svc 服务
5.0 daemonset
- 什么是 DaemonSet:DaemonSet 控制器是用来保证在所有节点上运行一个 Pod 的副本。当有节点加入集群时,也会为他们新增一个 Pod。当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
- DaemonSet 典型用法:
- 在每个节点上运行集群存储守护进程:gluster、ceph
- 在每个节点上运行日志收集守护进程:fluentd、filebeat、logstash
- 在每个节点上运行监控守护进程:prometheus、node_exporter
- 在每个节点上运行网络插件为 Pod 提供网络服务:flannel、calico
1 | apiVersion: apps/v1 |
5.1 示例
1 | # cat ds-demo.yaml |

5.2 部署 node_exporter
- 为每个节点运行一份 node_exporter,采集当前节点信息
1 | # cat ds-nodexport.yaml |

5.3 ds 更新策略
- ds 也支持更新策略,它支持 OnDelete 和 RollingUpdate:
- OnDelete:是在相应节点的 Pod 资源被删除后重建新版本,从而运行用户手动编排更新过程
- RollingUpdate:滚动更新,工作逻辑和 deploy 滚动更新类似
5.3.1 RollingUpdate
- 将此前创建的 node-expoter 中的 Pod 模板镜像修改为 v1.4.0,测试其更新过程
- 安装默认的 RollingUpdate 策略,node-exports-ds 资源将采用一次更新一个 Pod 对象,待新建 Pod 的对象就绪后,在更新下一个 Pod 对象,直到全部完成
1 | # cat ds-node-expoter.yaml |

5.3.2 OnDelete
- 将此前创建的 node-expoter 中的 Pod 模板镜像更新为 v1.5.0,由于升级版本跨度过大,无法确保升级过程中稳定性,我们就不得不适用 OnDelete 策略来替换默认的 RollingUpdate 策略
- 由于 OnDelete 并非自动完成升级,它需要管理员手动删除 Pod,然后重新拉起新的 Pod,才能完成更新。(对于升级有着先后顺序的软件这种方法就非常有用)
1 | # cat ds-node-expoter.yaml |

6.0 job、cronjob
- 什么是 Job:Job 控制器常用于管理那些运行一段时间就能够 “完成” 的任务,例如离线数据分析,数据备份等,当任务完成后,由 Job 控制器将该 Pod 对象至于 Complete 完成状态,在完成一定时间后,当达到用户指定的生存周期,由系统自动删除任务。如果容器中的进程因 “错误” 而终止,则需要依赖 RestartPolicy 配置来确定是否重启,如果是因为节点故障造成 Pod 意外终止的话,会被重新创建起来继续运行
- Pod 执行,退出状态为 0,则表示执行成功,而后将该 Pod 状态置于 Complete
- Pod 执行,退出状态码为非 0,检查 restartpolicy 为 Never,表示永不重启,而后该 Pod 状态置于 Failure
- Pod 执行,退出状态码为非0,检查 restartpolicy 为 OnFailure,表示退出状态码如果不为 0 时重启该 Pod,所以会尝试重新拉取 Pod,直到执行成功为止
- Job 工作方式:
- 实际生产环境中,有些任务可能需要运行不止一次,用户可以配置他们以串行或并行方式运行起来
- 串行 Job:将一个作业串行执行多次直到满足期望的次数
- 并行 Job:设定工作队列数,同时运行,而每个队列仅运行一个作业
- 注意:对于有严格次序要求的作业,只能选择串行执行,而没有严格次序要求的可以选择并行来运行的效率和速度
- 实际生产环境中,有些任务可能需要运行不止一次,用户可以配置他们以串行或并行方式运行起来
- job: 运行完便结束:消费者–> 程序 –> Dockerfile –> job –> pod
- cronjob: 定时执行:消费者–> 程序 –> Dockerfile –> cronjob –> job –> pod
6.1 job 基础资源
1 | # cat job-demo.yaml |
6.2 job 示例代码
1 | # cat job-demo.yaml |

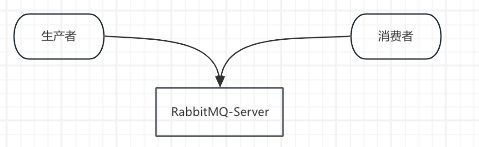
6.3 并行读取RabbitMQ数据演示
- 本例中,运行包含多个并行工作进程的 k8s job。文档中,每个 Pod 一旦被创建,会立即从任务重取走一个消息,然后将消息从队列中删除并退出本次任务
- 示例主要步骤:
- 启动一个消息队列服务:使用 RabbitMQ
- 创建一个队列,放上消息数据:每个消息表示一个要执行的任务
- 启动一个 Job,该 Job 启动多个 Pod:每个 Pod 从消息队列中读走一个任务,处理它,然后重复执行,知道队列的队尾
6.3.1 创建 RabbitMQ 服务
- RabbitMQ 消息队列服务
1 | # cat job-rabbitmq-server.yaml |
6.3.2 消息发布者
- 启动临时容器测试
1 | // 启动 ubuntu18.04 镜像,然后安装一些工具 |
6.3.3 消息订阅
创建镜像,获取数据,然后以 Job 方式运行起来
编写获取队列程序
1
2
3
4
5
6
7// 获取队列数据,然后等待 10s,结束
# cat worker.py
#!/usr/bin/env python
import sys
import time
print("Processing " + sys.stdin.readlines()[0])
time.sleep(10)编写 Dockerfile
1
2
3
4
5
6
7
8
9
10
11
12
13// 编写 Dockerfile 文件,制作为镜像,然后推送到自己的仓库;(注意镜像中需要传递的变量)
# cat Dockerfile
FROM ubuntu:18.04
RUN apt-get update && \
apt-get -y install curl ca-certificates amqp-tools python dnsutils --no-install-recommends \
&& rm -rf /var/lib/apt/lists/*
COPY ./worker.py /worker.py
RUN chmod +x /worker.py
CMD /usr/bin/amqp-consume --url=$BROKER_URL -q $QUEUE -c 1 /worker.py
# docker build -t rabbit-mq-consumer-job .
# docker tag rabbit-mq-consumer-job:latest harbor.inadm.com/inadm_kubernetes/rabbit-mq-consumer-job:latest
# docker push harbor.inadm.com/inadm_kubernetes/rabbit-mq-consumer-job:latest编写 Job 任务:每个 Pod 使用队列中的一个消息然后退出。这样, Job 的完成计数就代表了完成的工作项的数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# cat job-rabbitmq-consumer.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: rabbitmq-consumer
namespace: inadm
spec:
completions: 8 # 总共运行 8 次,因为队列中有 8 条消息
parallelism: 2 # 并行执行 2 个任务
ttlSecondsAfterFinished: 1000 # 结束后 1000s 删除
template:
spec:
imagePullSecrets:
- name: harbor-auth
containers:
- name: mq-consumer-work
image: harbor.inadm.com/inadm_kubernetes/rabbit-mq-consumer-job:latest
env:
- name: BROKER_URL
value: amqp://guest:[email protected]:5672
- name: QUEUE
value: job1
restartPolicy: OnFailure
# kubectl apply -f job-rabbitmq-consumer.yaml1
2
3
4
5
6
7
8# kubectl describe jobs rabbitmq-consumer -n inadm
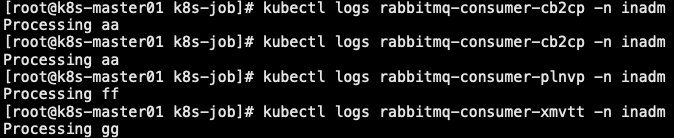
# kubectl logs reabbitmq-consumer-xxxx -n inadm # 通过检查 Pod 的 logs,可以看到消息被取走了
# kubectl describe jobs -n inadm rabbitmq-consumer # 检查 Job
// 如果设置的完成数量小于队列中的消息数量,会导致一部分消息项不会被执行
// 如果设置的完成数量大于队列中的消息数量,当队列中的所有的消息都处理完成后,Job 也会显示为未完成。Job 将创建 Pod 并阻塞等待消息输入。
// 当发生下面两种情况时,即使队列中所有消息都处理完成了,Job 也不会显示为完成状态
1. 在 amqp-consume 命令拿到消息和容器成功退出之间的时间段内,执行杀死容器操作
2. 在 kubectl 向 api-server 传回 Pod 成功运行之前,发生节点崩

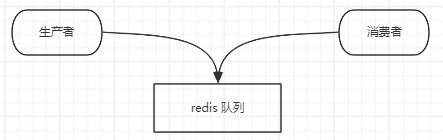
6.4 并行读取redis数据
- 运行一个 K8s Job,其中 Pod 会运行多个并行工作进程
- 在例子中,当每个 Pod 被创建时,它会从一个任务队列中获取一个工作单元,处理它,然后重复,直到达到队列尾部
- 启动 Redis 存储服务用于保存工作队列:在上一个例子中,使用了 RabbitMQ,但无法提供一个良好的方式来检测一个有限长度的工作队列是否为空,所以本次使用 Redis,和一个自定义的工作队列客户端
- 创建一个队列,然后向其中填充消息:每个消息表示一个将要被处理的工作任务
- 启动一个 Job 队列中的人物进行处理:这个 Job 启动了若干个 Pod。每个 Pod 从消息队列中取出一个工作任务,处理它,然后重复,直到到达队列的尾部
6.4.1 创建 Redis 服务
- 部署 redis 消息队列服务
1 | # cat job-redis-server.yaml |
6.4.2 消息发布者
1 | // 启动临时可交互的 Pod 用于运行 Redis 命令行 |
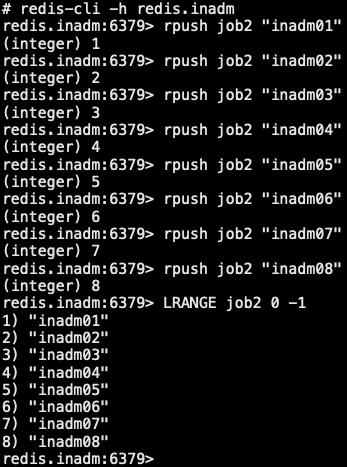
6.4.3 消息订阅
创建镜像,获取数据,然后以 Job 方式运行起来
编写获取队列程序:使用一个带有 Redis 客户端的 python 工作程序从消息队列中读出消息
rediswq.py 制作镜像中的一个文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 这里提供了一个简单的 Redis 工作队列客户端库,叫 rediswq.py。然后 Job 中每个 Pod 内的 "工作程序" 使用工作队列客户端库获取数据
# cat worker.py
#!/usr/bin/env python
import time
import rediswq
host="redis.inadm" # 连接 redis 的 svc 名称
q = rediswq.RedisWQ(name="job2", host=host)
print("Worker with sessionID: " + q.sessionID())
print("Initial queue state: empty=" + str(q.empty()))
while not q.empty():
item = q.lease(lease_secs=10, block=True, timeout=2)
if item is not None:
itemstr = item.decode("utf-8")
print("Working on " + itemstr)
time.sleep(10)
q.complete(item)
else:
print("Waiting for work")
print ("Queue empty, exiting")编写 Dockerfile
1
2
3
4
5
6
7
8
9
10# Dockerfile
FROM harbor.inadm.com/inadm_kubernetes/python:alpine3.15
RUN pip install redis
COPY ./worker.py /worker.py
COPY ./rediswq.py /rediswq.py
RUN chmod +x /worker.py /rediswq.py
CMD python worker.py
# docker build -t harbor.inadm.com/inadm_kubernetes/redis-mq-consumer-job:v1.0 .
# docker push harbor.inadm.com/inadm_kubernetes/redis-mq-consumer-job:v1.0编写 Job 任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# cat redis-consumer.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: redis-consumber
namespace: inadm
spec:
# completions: 1 # 默认 1
parallelism: 2
ttlSecondsAfterFinished: 1000
template:
spec:
imagePullSecrets:
- name: harbor-auth
containers:
- name: redis-consumber
image: harbor.inadm.com/inadm_kubernetes/redis-mq-consumer-job:v1.0
restartPolicy: OnFailure
# kubectl apply -f redis-consumer.yaml检查
1
2
3
4
5# kubectl describe jobs redis-consumber -n inadm
# kubectl logs -n inadm redis-consumber-jwstt
// 在这个例子中,每个 Pod 处理了队列中的多个项目,直到队列中没有项目时便退出。因为由工作程序自行检测工作队列是否为空,并且 Job 控制器不知道工作队列的存在,这依赖于工作程序在完成时发出信号。
// 工作程序以成功退出的形式发出信号表示工作队列已经为空。所以,只要有任意一个工作程序成功退出,控制器就知道工作已经完成了,所有的 Pod 将很快会退出。
// 因此,我们将 Job 的完成技术(Complateion count)设置为 1
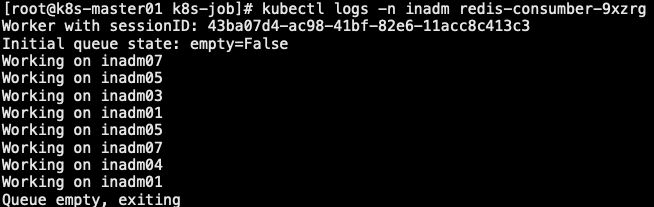
6.5 contjob
- 什么是 CronJob:CronJob 资源用于管理 Job 资源的运行时间,它允许用户在特定时间或指定时间运行 Job,它适合自动执行特定的任务,例如 备份、报告、发送邮件、垃圾清理。而一个 CronJob 对象就像 crontab 文件中的一行。它用cron 格式进行编写 分 时 日 月 周
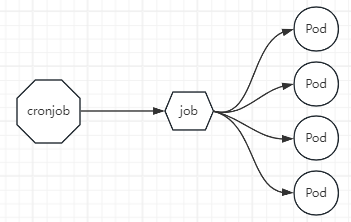
- CronJob 并发执行:CronJob 资源的 对象可能不支持同时运行多个实例,用户可基于 spec.concurrencyPolicy 属性来控制多个 CronJob 并存的机制
- Allow:运行不同时间点的多个 CronJob 实例同时运行(默认)
- Forbid:CronJob 不允许并发任务执行;如果新任务的执行时间到了而老任务没有执行完,CronJob 会忽略新任务的执行
- Replace:用于让后一个 CronJob 取代前一个,即终止一个并启动后一个
- 注意:并发性规则仅适用于相同 CronJob 创建的任务。如果有多个不同的 CronJob,它们相应的任务总是允许并发执行的
6.5.1 CrobJob 基础资源
1 | apiVersion: betach/v1 |
- CronJob 示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# cat cronjob-demo.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-demo
namespace: inadm
spec:
failedJobsHistoryLimit: 5 # 保留运行失败的 Job,5条
successfulJobsHistoryLimit: 5 # 保留运行成功的 Job,5条
startingDeadlineSeconds: 300 # 错误计划执行时间,而允许延迟启动的最长时间
schedule: "* * * * *" # 每分钟执行一次
jobTemplate:
spec:
parallelism: 1 # 并行执行为 1
completions: 1 # 需要成功运行 1 次
ttlSecondsAfterFinished: 3600 # Job 在结束 3600s 之后,会被系统自动删除(无论执行成功还是失败)
#activeDeadlineSeconds: 120 # 总活跃时间为 120s,包含运行 Pod时间+异常时间重试次数时间
template:
spec:
imagePullSecrets:
- name: harbor-auth
restartPolicy: OnFailure
containers:
- name: cronjob-container
image: harbor.inadm.com/inadm_kubernetes/tools:latest
command:
- "/bin/bash"
- "-c"
- "echo Hell From CronJob; sleep 5"
# kubectl apply -f cronjob-demo.yaml
# kubectl logs -n inadm cronjob-demo-29219016-p5dtn
Hell From CronJob

6.6 每分钟从redis队列获取数据
- 消费者–> 程序 –> Dockerfile –> cronjob –> job –> pod
6.6.1 消息发布者
1 | 1. 创建 redis 服务:参考 6.4.1 |
6.6.2 消息发布者
- 定期获取 Redis 中数据
1 | # cat redis-cronjob-consumber.yaml |
1 | // 检查 |
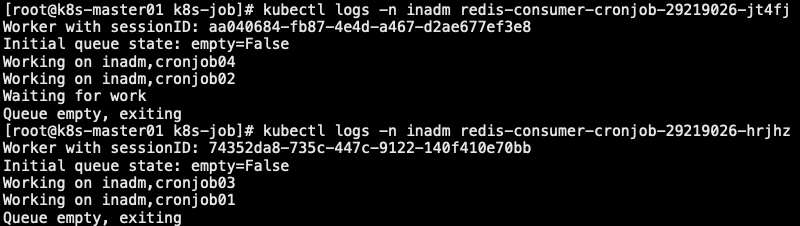
7.0 service
srevice 的作用:
- 暴露流量:让用户可以通过 ServiceIP + ServicePort 访问对应后端的 Pod 应用
- 负载均衡:提供基于 4 层的 TCP/IP 负载均衡,并不提供 HTTP/HTTPS 等负载均衡
- 服务发现:当发现新增 Pod 则自动加入至 Service 的后端,如发现 Pod 异常则自动剔除 Service 后端
service 工作逻辑:
- Service 持续监视 API-Server,监视 Service 标签选择器所匹配的后端 Pod,并实时跟踪这些 Pod 对象的变动情况,例如 IP 地址发生变化、或 Pod 对象新增与减少
- 不过 Service 并不直接与 Pod 建立关联关系,它们之间还有一个中间层 Endpoints,Endpoints 对象是由一个 IP 地址和端口组成的列表,这些 IP 地址和端口则来自于 Service 标签选择器所匹配到的 Pod,默认情况下,创建 Service 资源时,其关联的 Endpoints 对象会被自动创建
- Service:用户通过 kubectl 命令向 apiServer 发送创建 Service 请求,APIServer 收到后存入 etcd
- nedpoints:获取 Service 所匹配的 Pod 地址,而后将信息写入与 Service 同名的 endpoints 资源中
- kube-proxy:获取 Service 和 Endpoints 资源的变动,而后生存 iptables 、IPVS 规则,在本级执行
- iptables:当用户请求 service_ip 时,使用 iptables 的 DNAT 技术将 ServiceIP 的请求调度至 endpoint 保存 ip 列表
service 具体实现:
- 在 k8s 中,Service 只是抽象的一个概念,真正起作用实现负载均衡规则的其实是 kube-proxy 这个进程。它在每个节点上都需要运行一个 kube-proxy,来完成负载均衡规则的创建
- 创建 Service 资源后,会分配一个随机的 ServiceIP,返回给用户,然后写入 etcd
- endpoints controller 负责生成和维护所有 endpoints,它会监听 Service 和 Pod 的状态,当 Pod 处于 running 且准备就绪时,endpoints controller 会将 Pod IP 更新到对应 Service 的 endpoints 对象中,然后写入 etcd
- kube-proxy 通过 API-Server、Endpoints 的资源变动,一旦 Service 或 EndPoints 资源发生变化,kube-proxy 会将最新的信息转换为对应的 iptables、IPVS 访问规则,而后在本地主机执行
- 当客户端想要访问 Service 的时候,其实访问的就是本地节点上的 iptables、IPVS 规则,由他们路由到对应节点
- 在 k8s 中,Service 只是抽象的一个概念,真正起作用实现负载均衡规则的其实是 kube-proxy 这个进程。它在每个节点上都需要运行一个 kube-proxy,来完成负载均衡规则的创建
service 资源类型:
- ClusterIP:通过集群的内部 IP 暴露服务,选择 ServiceIP 只能够在集群内部访问。这也是默认的 ServiceType
- NodePort:NodePort 类型是对 ClusterIP 类型 Service 资源的扩展。它通过每个节点上的 IP 和端口接入集群外部流量,并分发给后端的 Pod 处理和响应。因此通过 < 节点IP >:< 节点端口 >,可以从几圈外访问服务
- loadBalance:这类 Service 依赖云厂商,需要通过云厂商调用 API 接口创建软件负载均衡将服务暴露到集群外部。当创建 LoadBalance 类型的 Service 对象时,它会在集群上自动创建一个 NodePort 类型的 Service。集群外部的请求流量会先路由该负载均衡,并由该负载均衡调度至各个节点的 NodePort
- ExternalName:此类型不是用来定义如何访问集群内服务的,而是把集群外部的某些服务以 DNS、CNAME 方式映射到集群内,从而让集群内的 Pod 资源能够访问外部服务的一种实现方式
7.1 配置示例
1 | apiVersion: v1 |
7.1.1 ClusterIP
1 | apiVersion: v1 |
7.1.2 NodePort
1 | # cat svc-nodeport.yaml |

7.1.3 ExternalName
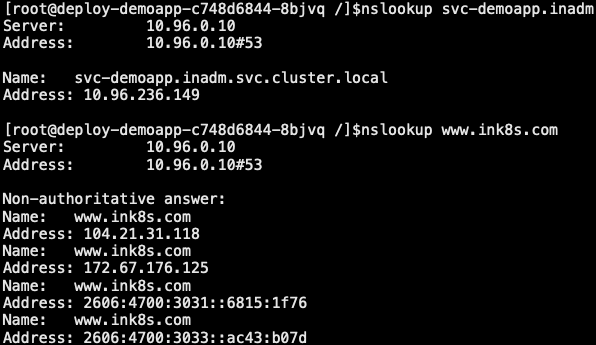
- 当查询主机 SERVICE.NAMESPACE.svc.cluster.local 时,集群的 DNS 服务将返回一个值为 www.ink8s.com 的 CNAME 记录访问这个服务的工作方式与其它的相同,唯一不同的是重定向发生在 DNS 层面
1 | # cat pod-test.yaml |
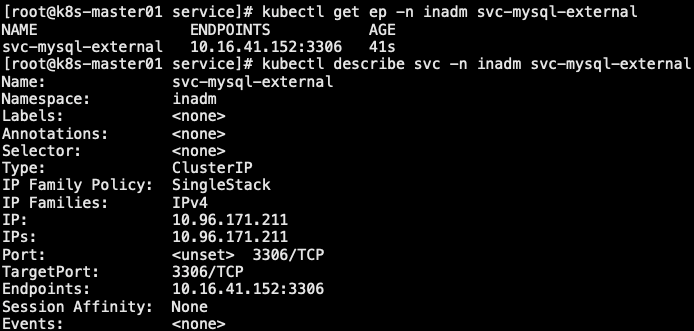
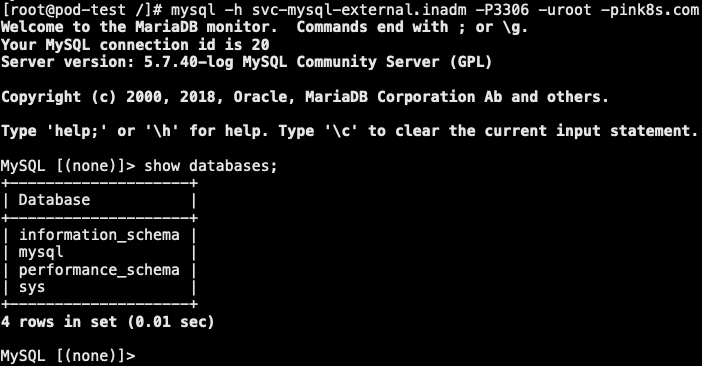
7.2 自定义endpoint
- service 通过 selector 和 Pod 建立关联,k8s 会根据 关联到的 PodIP 信息组合成一个 endpoint。若 service 定义中没有 selector 字段,service 被创建时,endpoint controller 不会自动创建 endpoint
- 我们可以通过配置清单创建 service,而无需使用标签选择器,而后自行创建一个同名的 endpoint 对象,指定对应的 IP。这种一般用于将外部 MySQL、Redis 等应用引入 k8s 集群内部,让内部通过 service 的方式访问外部资源
1 | // 1. 准备外部 MySQL 服务,并且允许远程用户访问权限 |
7.3 service相关字段
7.3.1 sessionAffinity
- 如果要将来自于特定客户端的连接调度至同一 Pod,可以使用 sessionAffinity 基于客户端的 IP 地址进行会话保持
- 还可以通过 sessionAffinityConfig.clientIP.timeoutSeconds 来设置最大会话停留时间。(默认 10800s,即 3H)
1 | # cat deploy-demoapp.yaml |

7.3.2 externalTrafficPolicy
- 外部流量策略:当外部用户通过 NodePort 请求 Service,是将外部流量路由到本地节点上的 Pod,或是路由到集群范围的 Pod
- Cluster(默认):将用户请求路由到集群范围的所有 Pod 节点,具有良好的整体负载均衡
- Local:仅会将流量调度至请求的目标节点本地运行的 Pod 对象之上,以减少网络跳跃,降低网络延迟,但当请求指向的节点本地不存在目标 Service 相关的 Pod 对象时直接丢弃该报文
1 | # cat svc-externaltraffice.yaml |


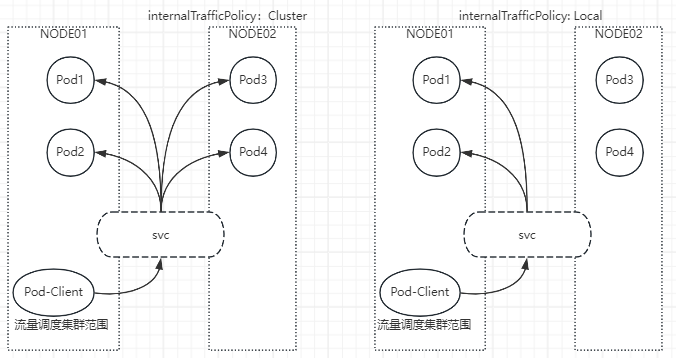
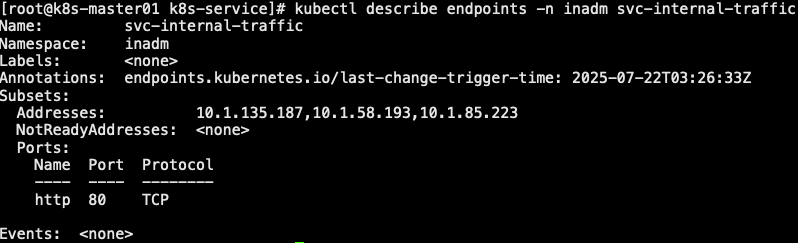
7.3.3 internalTrafficPolicy
- 本地流量策略:当本地 Pod 对 Service 发起访问时,是将流量路由到本地节点上的 Pod,还是路由到集群范围的 Pod
- luster (默认):将 Pod 的请求路由到集群范围的所有 Pod 节点,具有良好的整体负载均衡
- Local:将请求路由到与发起方处于相同节点的端点,这种机制有助于节省开销,提升效率。但当请求指向的节点本地不存在的目标 Service 相关的 Pod 对象时直接丢弃该报文
- 注意:在一个 service 上,当 externalTrafficePolicy 已设置为 Local 时,internalTrafficPolicy 则无法使用。换句话说,在一个集群的不同 service 上可以同时使用这2个特性,但在一个 service 上不行
1 | # cat svc-internal.yaml |

7.3.4 publishNotReadyAddresses
- publishNotReadyAddresses: 表示 Pod 就绪探针探测失败,也不会将失败的 PodIP 加入 NotReadyAddresses 列表中
1 | # cat publishNRA.yaml |
7.4 coredns 策略
- DNS 策略可以单独对 Pod 进行设定,在创建 Pod 时可以为其指定 DNS 的策略,最终配置会落在 Pod 的 /etc/resolv.conf 文件中,可以通过 pod.spec.dnsPlicy 字段设置 DNS 的策略
1 | // 下面演示环境需要的配置 |
7.4.1 ClusterFirst
- ClusterFirst (默认DNS策略):表示 Pod 内的 DNS 使用集群中配置的 DNS 服务,简单来说就是使用 k8s 中的 coredns 服务进行域名解析。如果解析不成功,会使用当前 Pod 所在的宿主机 DNS 进行解析
1 | # cat dns-clusterfirst.yaml |
7.4.2 ClusterFirstWithHostNet
- 某些场景下,我们的 Pod 是用 HostNetwork 模式启动的,一旦使用 Hostnetwork 模式,那该 Pod 则会使用当前宿主机的 resolv.conf 来进行 DNS 查询,但如果任然继续使用 k8s 的 DNS 服务,那就将 dnsPolicy 设置为 ClusterFirestWithHostNet
1 | # cat dns-withhostnet.yaml |
7.4.3 Default
- 默认使用宿主机的 resolv.conf 但可以使用 kubelet 的 –resolv-conf=/etc/resolv.conf 来指定 DNS 解析文件地址
1 | # cat dns-default.yaml |
7.4.4 None
- 空的 DNS 设置,这种方式一般用于自定义 DNS 配置的场景,往往需要和 dnsConfig 一起使用才可以达到自定义的 DNS 的目的
1 | // 如果生产环境不便于 apply 应用文件,则可以采用 edit 修改 svc 然后将 svc 文件调整好待下次更新时调整及下次 apply 永久生效 |
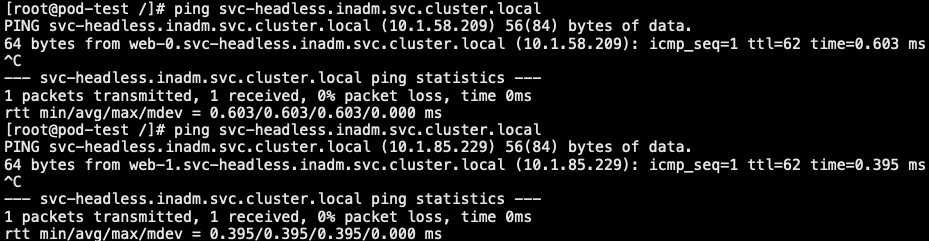
7.5 headless
- 什么是 HeadLess:HeadlessService 也叫无头服务,就是创建的 Service 没有 ClusterIP,而是为 Service 所匹配的每个 Pod 都创建一条 DNS 的解析记录,这样每个 Pod 都有一个唯一的 DNS 名称标识身份,访问的格式如 [SERVICE_NAME.NAMESPACE.svc.cluster.local]
- HeadLess 作用:像 elasticsearch、mongodb、kafka 等分布式服务,在做集群初始化时,配置文件中要写上集群中所有节点的 IP(或是域名)但 Pod 是没有固定 IP 的,所以配置文件里写 DNS 名称是最合适的
- 那为什么不用 service,因为 service 作为 Pod 前置负载均衡,一般是为一组相同的后端 Pod 提供访问入口,而且 service 的 selector 也没有办法区分同一组 Pod 的 不同身份
- 但是我们可以使用 statefulset 控制器,它在创建每个 Pod 的时候,能为每个 Pod 做一个编号,就是为了能区分这一组 Pod 的不同角色,各个节点的角色不会变的混乱,然后再创建 headless service 资源,集群内的节点通过 Pod名称+序号.service名称,来进行彼此间通信的,只要序号不变,访问就不会出错
- {statefulSet name}-{编号}.{headless service}.{namespace}.svc.cluster.local
1 | # cat headless.yaml |

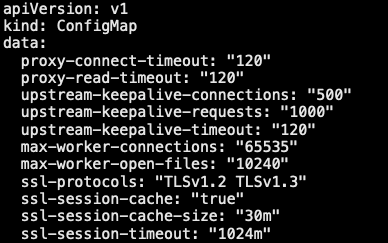
8.0 ingress
8.1 ingress 资源清单
1 | apiVersion: networking.k8s.io/v1 # 资源所属的 API 群组和版本 |
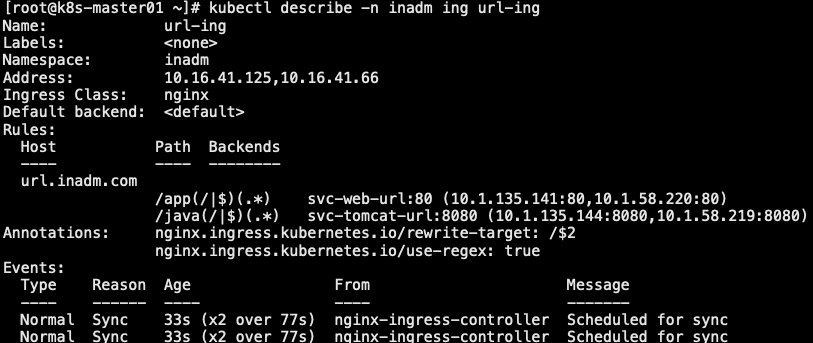
8.2 ingress 基于 url 实现路由
- 将来自同一域名,不同 URL 请求调度到不同 svc
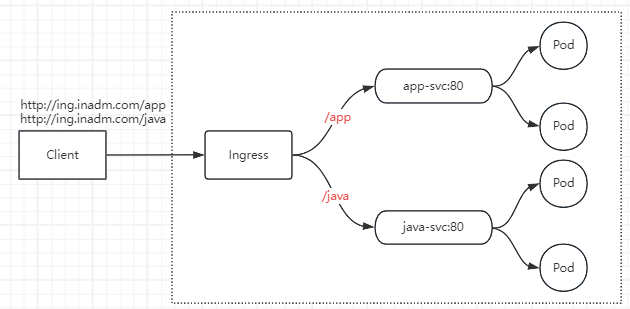
- 因后端 Pod 无法处理 /app 这样的接口,所以需要调整代理到后端的路径
- 默认 URL:用户请求 url.inadm.com/app,代理到后端请求也会带上 /app,后端无法处理该 url,就会报错
- 修改 URL:用户请求 url.inad.com/app,代理到后端后,将请求的 /app 删除,url 为 url.inadm.com/
8.2.1 demoapp 应用
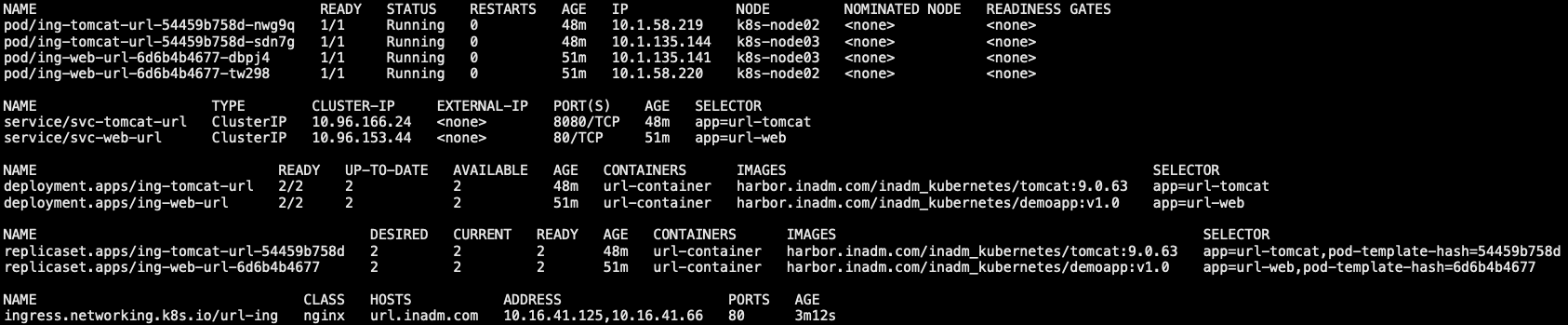
1 | # cat ing-deploy-web.yaml |
8.2.2 tomcat 应用
1 | # cat ing-deploy-tomcat.yaml |
8.2.3 ing 配置
1 | # cat ing-web-tomcat.yaml |
8.2.4 验证
8.3 多域名
- 将来自不同域名的请求调度到不同 svc
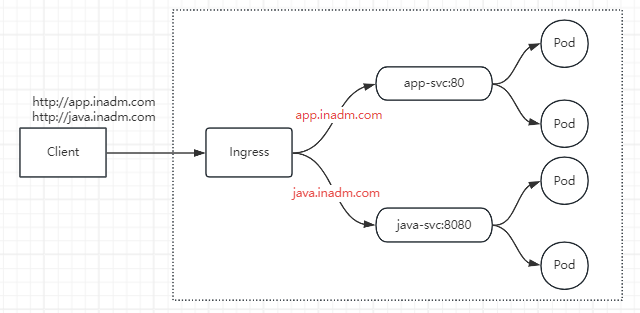
8.3.1 app 应用
1 | # cat ing-app-domian.yaml |
8.3.2 tomcat 应用
1 | # cat ing-tomcat-domian.yaml |
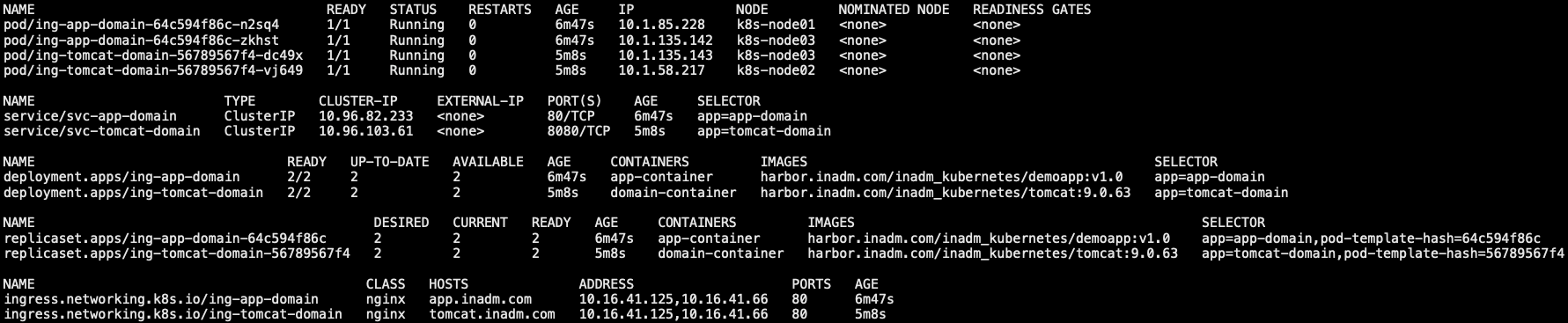
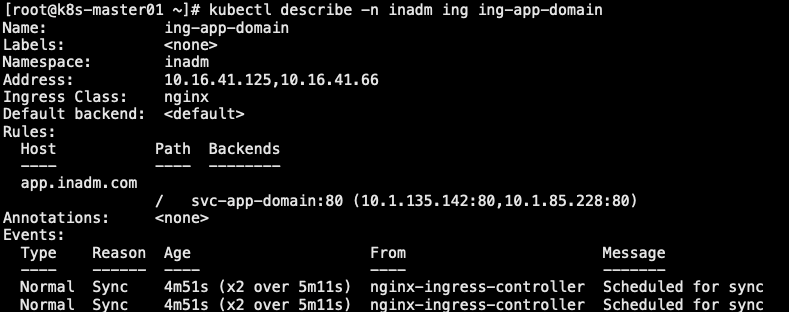
8.3.2 验证
8.4 ing 实现 https
- 在 ingress 中引用 secret 资源,然后告诉 Ingress 控制器使用 TLS 加密从客户端到负载均衡的通道
1 | // 创建 secrets (证书文件提前准备好) |
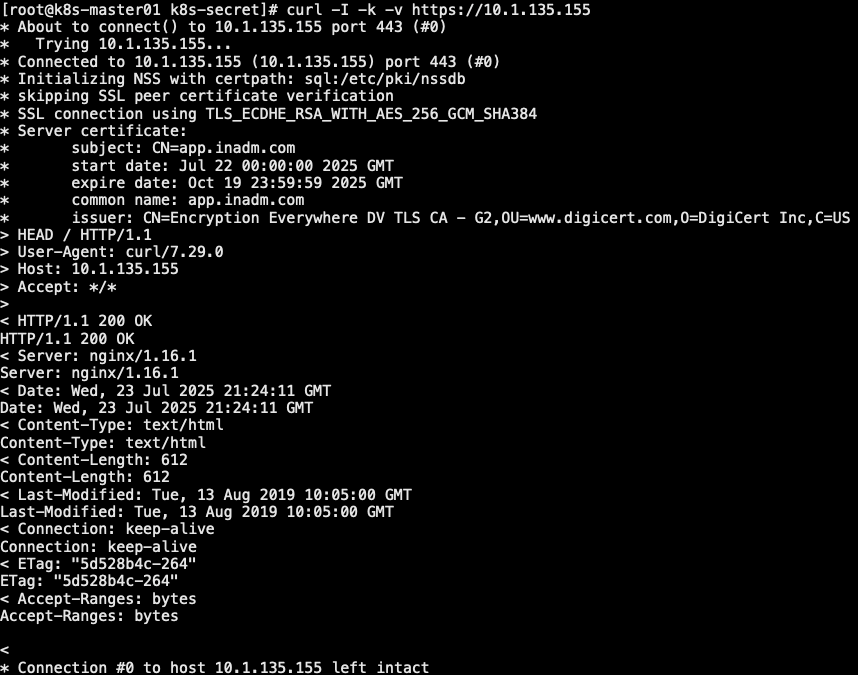
- 浏览器访问: https://app.inadm.com
8.5 ing 自定义配置
- annotations: 局部 –> server {} ==> 认证、限速 …
- configmap: 全局 –> http {} ==> 参数优化、压缩 …
8.5.1 自定义 basic 认证
1 | # yum -y install httpd-tools |
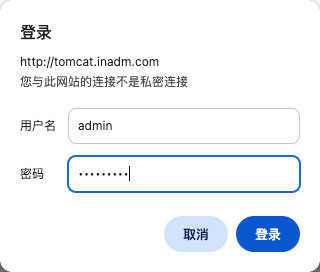
8.5.2 全局参数优化
- 如果相对 ingress 进行全局配置,可以通过 configmap 资源来实现,Pod 默认加载了一个 ConfigMap 资源 “ingress-nginx”
1 | # kubectl get cm -n ingress-nginx ingress-nginx-controller |

9.0 configmap
9.1 创建 cm
9.1.1 命令创建 cm
1 | // 1.使用 kubectl create configmap 命令 使用 --from-literal 选项给出键值对来创建 ConfigMap |
9.1.2 文件创建 cm
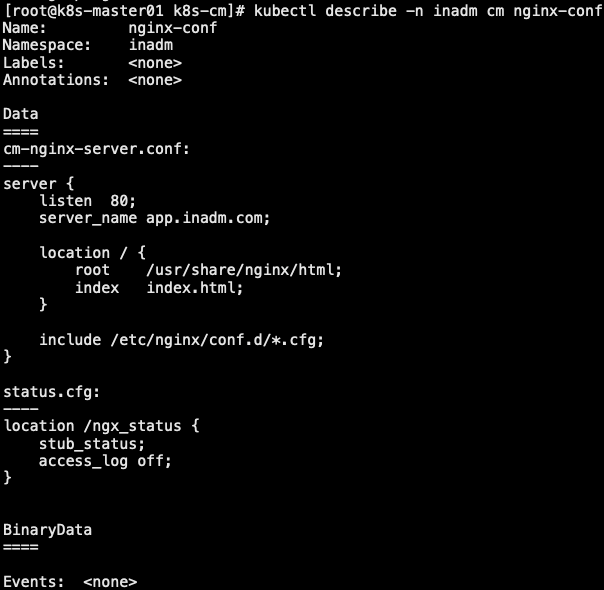
- cm 资源也可以为应用程序提供大段配置,这些大段配置通常保存在一个或多个文件中,可以使用 kubectl create cm 命令,通过 –from-file 选项一次加载一个配置文件的内容为指定的键值。默认文件为 key,文件内容为 values
1 | # cat cm-nginx-server.conf |
9.1.3 目录创建 cm
- 对于配置文件较多且无需自定义键名称的场景,可以直接在 kubectl cm 命令的 –from-file 选项上附加一个目录路径就能将该目录下的所有文件创建于同一个 cm 资源中,各文件名即为键名称
1 | # ls k8s-cm 目录中包含如下3个文件 |
9.1.4 yaml 文件创建 cm
1 | # cat cm-app-config.yaml |
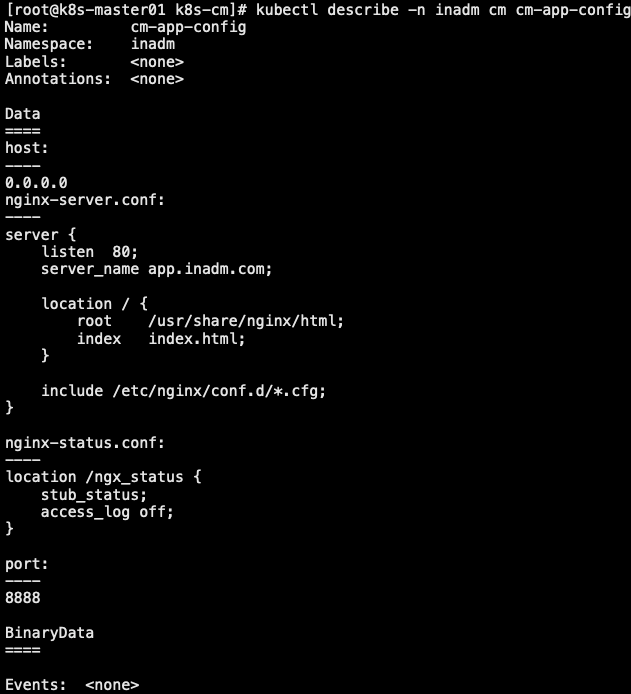
9.2 引用 cm
- 通过环境变量引用 cm 键值
- Pod 清单中除了使用 value 字段直接给定变量之外,还支持 valueFrom 字段嵌套 configMapKeyRef 来引用 ConfigMap 对象的键值,具体格式如下
1 | env: |
9.2.1 env 引用变量
1 | # cat cm-env-conf.yaml |

9.2.2 挂载卷引用 cm
- 使用环境变量方式导入 cm 对象中来源较长的文件内容,会导致占据过多的内存空间,同时也不支持内容的动态更新
- 其次该类数据主要用于为容器提供配置文件,所以将其内容直接通过挂载方式进行引用,会是一种更好的选择
- 引用了 9.1.3
1 | // 引用整个存储卷:将 cm 对象的每个键名转为容器挂载点路径下的一个文件名,所以每个建明应该设计为对容器应用加载的配置文件名称 |

9.2.3 引用存储卷部分键值
- 有些应用场景中,用户可能期望仅向容器中挂载指定几个键,例如前面创建名为 cm-app-config 里面有 4 个键,其中 host、port 能为 demoapp 容器定义监听地址及端口,而 nginx-server.conf 、nginx-status.conf 能为 nginx 提供一个虚拟主机站点以及该虚拟站点的状态信息
1 | # cat cm-app-config.yaml |
1 | # cat cm-nginx-demoapp.yaml |

9.2.4 引用存储卷单个键值
- 前面两种方式中,无论是装在 cm 对象中的所有文件还是部分文件,挂载点目录下原有的文件都会被隐藏。(打开刚在创建的 nginx 容器验证,看默认的 default.conf 配置文件是否还存在)
- 对于期望将 cm 对象提供的配置文件补充在挂载点目录下的需求来说,这种方法难以实现,好在我们可以通过容器上的 volumeMounts 字段 subpath 来解决
1 | // 1.运行一个 nginx_Pod,将 cm-app-config 中 nginx-server.conf、nginx-status.conf 挂载进来测试 |

9.3 redis 结合 cm
- 使用 redis 配置的值创建一个 cm 文档
- 创建一个 redis_pod,挂载并使用创建的 cm
- 验证配置已经被正确应用
1 | # cat cm-redis.yaml |
10.0 secret
- secret 资源类别:
- docker-registry:用于认证 Docker Registry 的 Secret,以便于用户能使用私有容器镜像
- generic:基于本地文件、目录或命令行创建的 Secret,一般用于存储密码、秘钥、等信息
- tls:基于指定的公钥和私钥对来创建 TLS Secret,专用于 TLS 通信
10.1 创建 secret
10.1.1 命令创建 secret
- 使用 secret 为容器中运行的服务提供用于认证的用户名和密码是一种常见的应用场景,像 MySQL 镜像就支持通过环境变量来设置管理员用户的默认密码
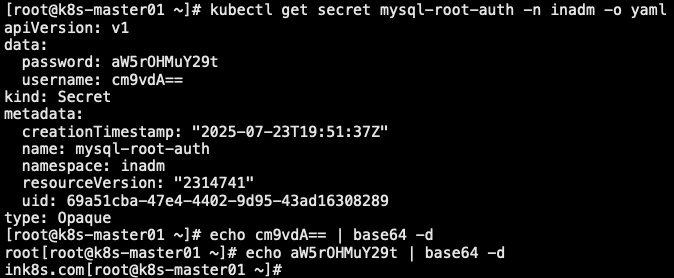
1 | // 比如: 创建一个名为 mysql-root-auth 的 secret 资源,用户名使用 username 键名,密码使用 password 键名 |
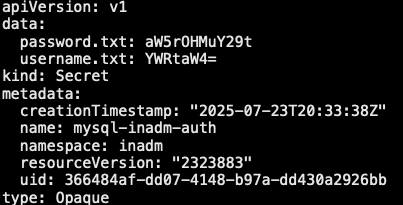
10.1.2 文件创建 Secret
- Secret 中包含 Pod 访问数据库所需的用户凭证,除了通过命令行创建,也可以通过文件方式创建。将用户名存储在文件 username.txt 中,将密码存储在文件 password.txt 中
1 | // 1.准备好对应的用户名文件以及密码文件 |
10.1.3 TLS secret
1 | # kubectl create secret tls app-inadm-com -n inadm --key=app.inadm.com.key --cert=app.inadm.com.pem |
10.1.4 docker registry
1 | # kubectl create secret docker-registry image-auth \ |
10.1.5 secret 清单
1 | // 1. 创建一个用户名 admin ,密码为 ink8s.com 的 Secret 对象,首先 用户名和密码做 base64 编码 |
1 | // 2. 通过 Data 定义资源清单需要实现进行编码,如果使用 stringData 则直接输入明文信息,而后程序自动完成编码存储至 Data |
10.2 pod 引用 secret
10.2.1 env 引用 Secret
- Pod 资源以环境变量方式获取 Secret 数据,存在两种方式
- 将指定键传递给环境变量,一个一个传递,通过 env.valueFrom 字段实现
- 将 Secret 对象上的全部键一次性全部映射为容器的环境变量,通过 envFrom 字段实现
1 | // 将此前创建 secret-demo01 变量挨个传递给系统环境变量,将 secret-demo02 一次导入到系统环境变量 |

10.2.2 MySQL 注入密码
1 | // MySQL 运行时初始化 root 用户的密码,引用此前创建的 secret 对象 mysql-root-auth |
10.2.3 引用整个存储卷
1 | // 引用整个存储卷:将 mysql-inadm-auth ,这个 secret 的每个键名转为容器挂载点路径下的一个文件名 |

10.2.4 引用部分存储卷
1 | // 1.将 mysql-inadm-auth,这个 secret 的 username.txt 键挂载至容器的 /app 目录下,命名为 username.txt |
10.3 nginx 基于 secret 实现 tls
- 场景说明:
- 运行一个 nginx 容器
- nginx 虚拟站点配置文件来源于 ConfigMap
- nginx 虚拟站点需要使用 TLS 证书,来源于 Secret
- 验证 nginx 服务是否已提供 https 访问
1 | # kubectl create secret tls web-inadm-com -n inadm --key=app.inadm.com.key --cert=app.inadm.com.pem |
11.0 statefulset
- StatefulSet 名称是固定,且创建时按照顺序进行创建,并固定对应的 Pod 名称
- Headless Service 用来配置每个 Pod 的 DNS 名称,只要 Pod 名称不变化,他们的 DNS 就是稳定且持久的
- VolumeClaimTemplate 作为分布式,每个 Pod 的数据时不一样的,所以每个 Pod 应该有自己的专有数据,所以他们不能使用同一个存储卷,应该使用各自自己的存储卷
1 | // StatefulSet 示例配置 |
11.1 sts 实践
- 创建名为 web-svc 的 Headless Service 用来控制网络域名
- 创建名为 web 的 StatefulSet 有一个 spec,它表名将在独立的 3 个 Pod 副本中启动 nginx 容器
- volumeClaimTemplates 将通过 PersistentVolumes 驱动来提供稳定的存储
1 | # cat sts-web-svc.yaml |
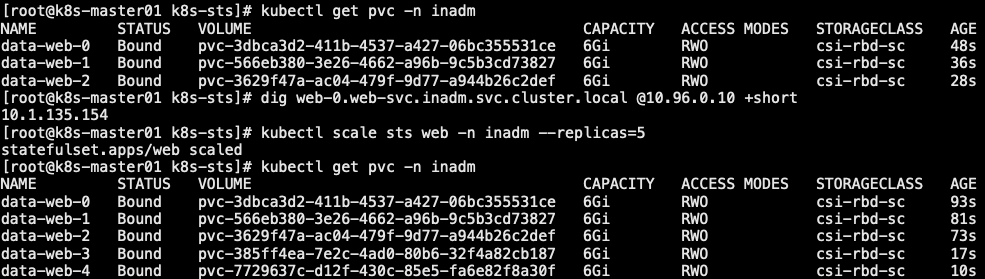
11.2 sts 更新策略
- sts 更新支持两种策略 onDelete 和 RollingUpdate,在 .spec.updateStrategy 进行设定
- onDelete: 当 StatefulSet 的 .spec.updateStrategy.type 设置为 OnDelete 时,控制器将不会自动更新 StatefulSet 中的 Pod。用户必须手动删除 Pod 以便让控制器创建新的 Pod,以此来对 StatefulSet 的 .spec.template 的变动做出反应
- RollingUpdate: RollingUpdate 更新策略对 StatefulSet 中的 Pod 执行自动的滚动更新。这是默认的更新策略。StatefulSet 控制器会删除和重建 Pod。它将按照与 Pod 终止相同的顺序(从最大序号到最小序号)进行,每次更新一个 Pod
11.2.1 滚动更新
1 | // 滚动更新:修改 yaml 为 RollingUpdate,并更新镜像版本 |

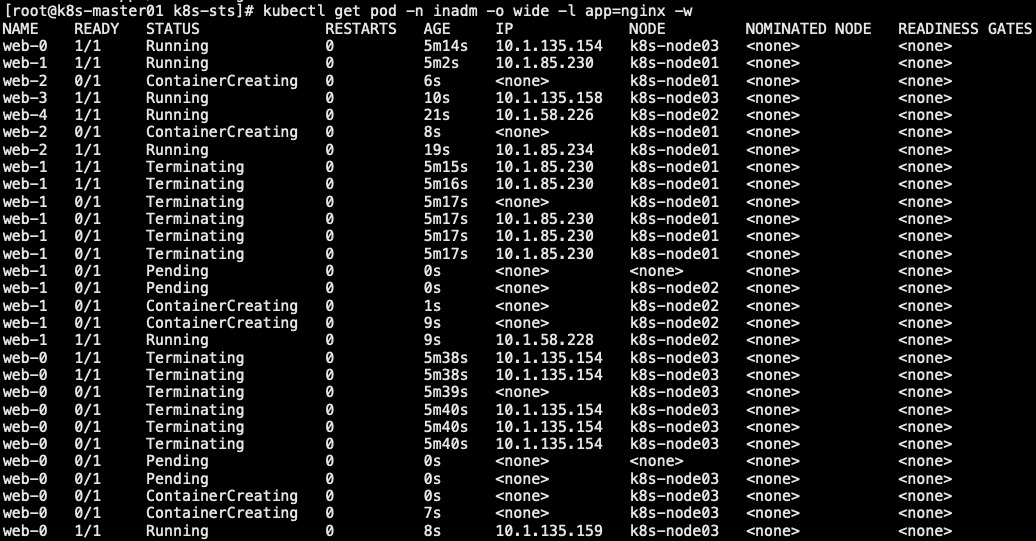
11.2.2 分区滚动更新
- sts 的 RollingUpdate 滚动更新支持 Partition 分区更新,有点类似灰度发布模式
- 设定 partition 为 3, sts 会检查是否有 Pod 的编号大于 3 ,如果有则更新大于等于 N 的 Pod
- 如果直接 partition 分区为 0,sts 会更新所有的镜像 (从最大序号到最小序号进行镜像更新)
1 | # cat sts-web.yaml |
12.0 认证与授权
- 为何需要认证:对于 k8s 系统来说,APIServer 肯定不是任何人都能轻易访问的,如果任何人都能轻易访问,意味着可以通过 kubectl 命令访问 APIServer,进而操作 k8s。也就意味着它能够在我们的系统上随便部署应用程序,甚至还会删除我们正在运行的应用程序,这是非常危险的。所以我们需要对用户进行身份认证,确保身份是合法的
- 认证流程:任何客户端用户试图通过 APIServer 操作资源对象时,他们必须经历多个阶段的访问控制,才会被接受处理,其中包含认证、授权及准入控制
- 认证:任何客户端访问,经过 API 操作之前,需要先完成认证操作,也就是进行身份认证
- 授权:认证通过后仅代表它是一个合法的系统用户,但它是否拥有删除对应资源权限,需要进行授权检查
- 准入控制:虽然我们有了权限,也可以创建 Pod 资源等各种资源,但创建 Pod 是否能够成功呢,假设 ops 名称空间显示最多创建 2 个 Pod,目前已经有了 2 个 Pod 了,那么这次的创建就会失败
- 认证的方式:
- UserAcconunt:使用 kubectl 创建资源,首先要进行客户端身份认证,所以客户端每次请求 APIServer 时都会携带上数字证书,用于认证 API-Server,当认证通过后,证书中的 Subject 将被识别为用户标识,其中的 CN 字段的值为用户名,字段 O 的值就是用户所属的组,例如:Subject: O=ops,CN=user01 用户名为 user01,用户的组为 ops
- ServiceAccount:有些情况下,期望在 Pod 内部能够访问 API-Server,获取集群的信息,甚至对集群进行改动。针对这种情况,k8s 提供了一种特殊的认证方式:ServiceAccount。默认情况下,创建的 Pod 如果没有指定 ServiceAccount 则系统默认提供一个 ServiceAccount,而后通过 mount 方式挂载到 Pod 文件系统,该 ServiceAccount 能通过 DownWardAPI 获取该 Pod 相关的一些元数据信息。当然也可以自行创建 ServiceAccount 来完成 API-Server 的身份认证,至于能否对集群进行改变,则需要看该 ServiceAccount 是否拥有权限
1 | // 可以使用 echo xxx | base64 -d 对 client-certificate-data 进行超管的解码 |
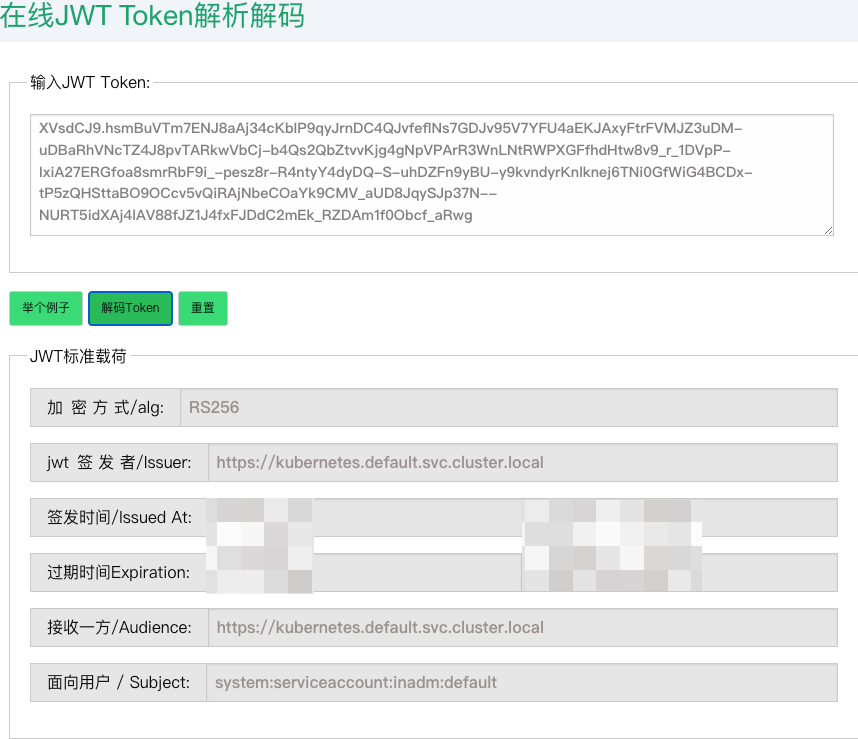
12.1 SA 认证实践
- 在线 JWT Token 解析解码
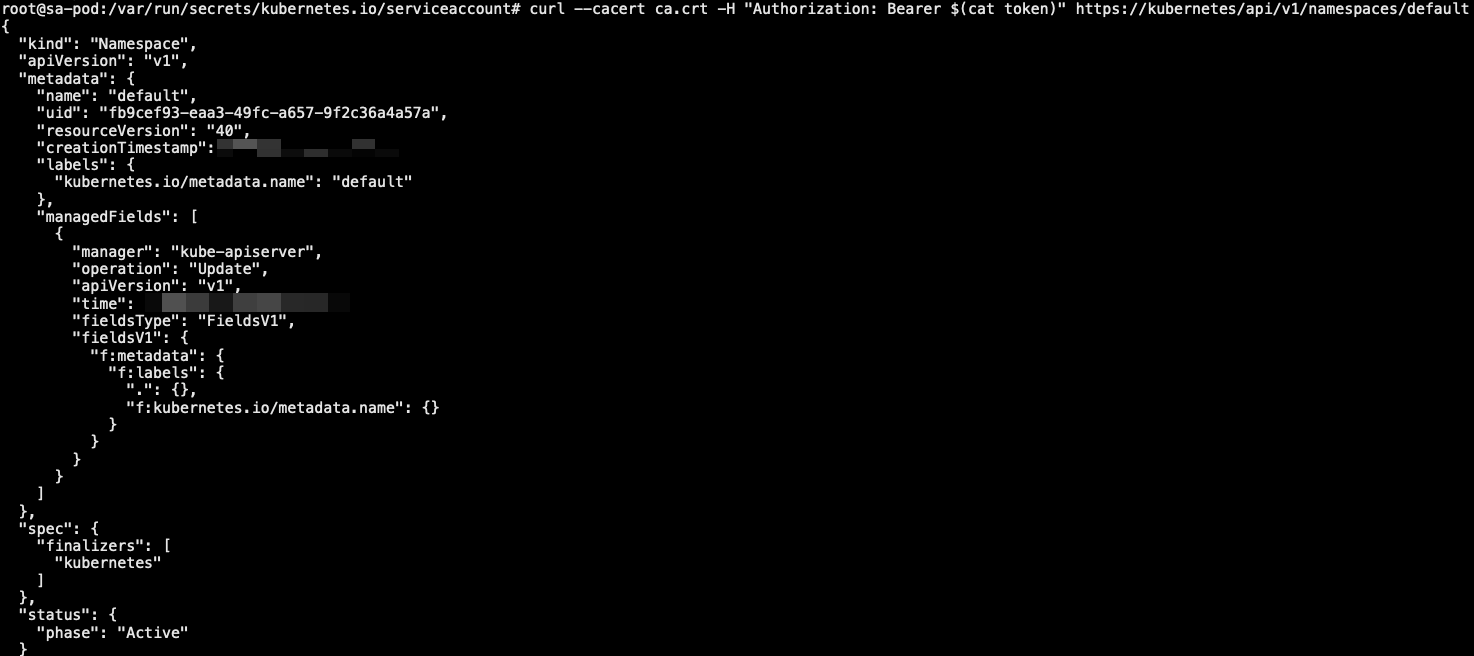
- 使用默认 sa 认证 API:当创建 Pod 时,如果没有指定 SA,Pod 会注入对应名称空间的 default 服务账户。如果你查看 Pod 的原始 YAML(例如:kubectl get pod/podname -o yaml),你可以看到 spec.serviceAccountName 字段已经被自动设置了
1 | # kubectl get pod -n inadm pod-test -o yaml | grep "serviceAccountName" |

12.1.1 创建 sa 并与 Pod 关联
1 | // 命令方式创建 SA |
- 测试 SA 用户能否认证 APIServer
1 | // Pod 清单文件应用 SA |

- 分配集群管理员权限,测试效果
1 | # kubectl create rolebinding role-sa-admin --clusterrole=admin --serviceaccount=default:sa-test |
12.1.2 sa 添加私有仓库认证
- 通过 ServiceAccountName 来完成私有仓库认证,可以不使用 imagePullSecret,因为在 ServiceAccount 中有 Image Pull Secrets 这个字段,可以将认证仓库信息给附加进去
1 | // 1.secret 认证使用 harbor-auth |
12.2 k8s 基于 user 认证
- kubeconfig 作用:由于 APIServer 是基于无状态 HTTP/HTTPS 协议实现,所以每次与集群进行交互都需要进行身份认证,通常都是使用证书进行认证,其认证所需要的信息都会存放在 kubeconfig 文件中
- 客户端程序会通过默认路径 -–kubeconfig 选项 或 KUBECONFIG 环境变量定义要加载的 kubeocnfig 文件,从而能够在每次的请求通过 API-Server 的认证
- kubeconfig 文件格式:kubeconfig 文件主要分为四部分:cluster、users、context、current-context
- cluster:集群以列表形式定义在 cluster 配置段中,每个列表项代表一个 kubernetes 集群,并拥有名称标识
- users:访问集群的身份都定义在 users 配置段中,每个列表项代表一个能够认证到某个 kubernetes 集群的凭据
- context:将 user 与 cluster 二者之间的映射关系进行绑定,而后定义在 context 配置中
- current-context:用于指定当前集群默认使用的 context,表示当前正在使用哪个用户操作哪个集群
1 | // 默认使用 kubeadm 初始化 kubernetes 集群过程中,在 master 节点上生成的 /etc/kubernetes/admin.conf 文件就是一个 kubeconfig 格式的文件,它由 kubeadm 命令自动生成,可由 kubectl 加载后接入当前集群的 API Server。 |
12.2.1 自定义 kubeconfig
- 创建一个 UserAccount 用户,然后加入到 kubeconfig 文件中,最后通过 kubectl 加载 kubeconfig 文件中对应的证书信息,然后尝试认证到 APServer
- UserAccount 用户不可以直接创建,需要创建证书文件,在证书申请文件中填写好证书对应的 CN,也就是我们的用户名称,而后经由 APIServer 信任的 CA (/etc/kubernetes/api/ca.crt) 签署证书请求文件。最后与 APIServer 进行认证时,APIServer 会获取证书中的 CN,以判断该用户是否是合法的
- 加入已有集群配置文件
1 | // 创建证书私钥文件 |
12.2.2 创建新的集群配置文件
1 | // 1.添加集群配置,设定集群名称,设定 APIServer 地址,以及 APIServer 信任的 CA 证书 |
1 | [root@master01 ~]# kubectl config current-context # 查看 kubectl 的当前上下文 |
12.3 RBAC 授权
- RBAC 基于角色的访问控制;其实就是将资源的操作权限授予给指定的角色,而后将用户加入该角色,那么该用户则拥有了对角色的权限
- 举例:希望 user01 用户能够获取所有 Pod 的列表
- 首先定义角色,然后定义角色权限规则,资源:Pod,操作权限:get,list
- 然后定义角色绑定,将 user01 绑定至该角色,而后 user01 就拥有了该角色的权限,进而就能够获取 Pod 信息
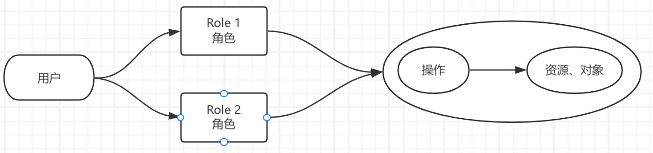
- RBAC 角色与集群角色:k8s 系统的 RBAC 授权插件将角色分为了 Role 和 ClusterRole 两类:
- Role:仅作用于名称空间级别,用于承载名称空间级别内的资源权限集合
- ClusterRole:作用于集群范围,能够同时承载名称空间和集群级别的资源权限集合
- k8s 利用 Role 和 ClusterRole 两类角色来赋予对应的权限,同时也需要用到另外两类资源 Rolebinding 和 ClusterRolebinding 来完成用户与角色的绑定关系
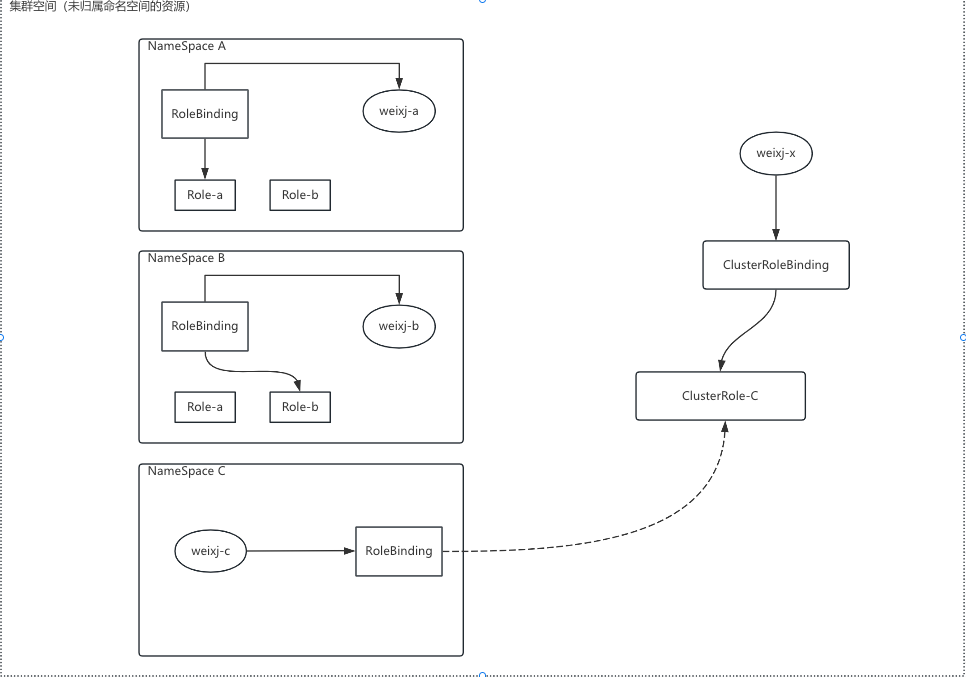
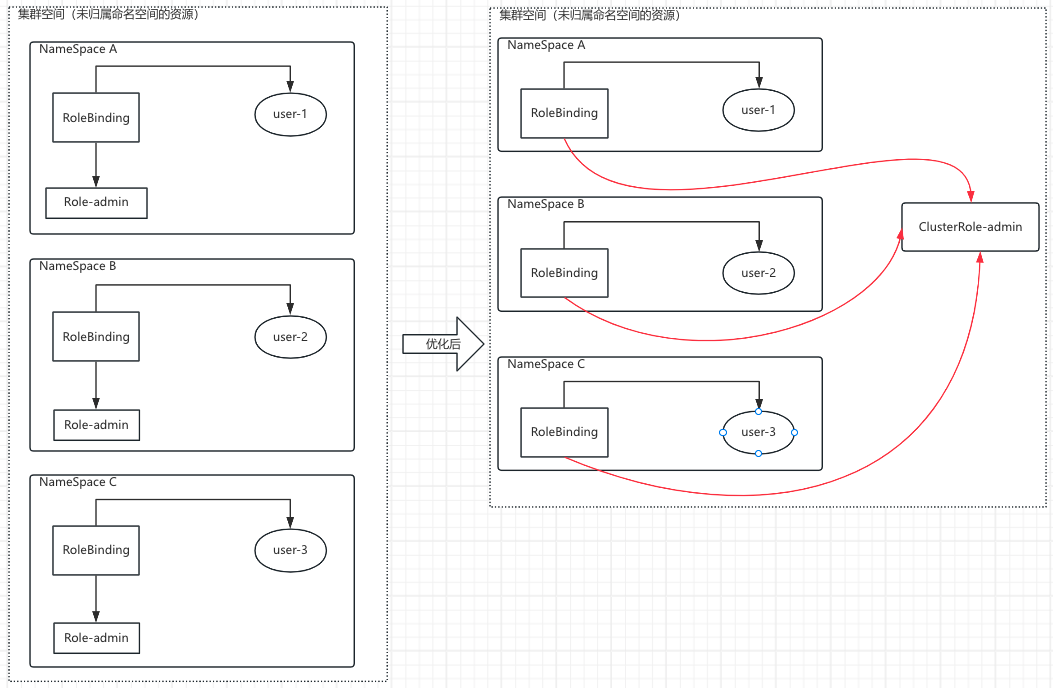
- 注意:RoleBinding除了可以绑定 Role 以外,还可以绑定 ClusterRole,但它的权限还是限制在名称空间级别
- 这种方式有着特定的应用场景
- 比如:希望在三个名称空间中都创建一个管理员身份,那么我们就需要创建3个 role 和 3 个 rolebinding
- 但是:我们可以定义一个 clusterrole,然后通过 rolebind 绑定就完成了,也就不需要重复创建很多的 role
- 这种方式有着特定的应用场景
1 | Role <-- Rolebinding --> User |
12.3.1 RBAC 场景-1
- 场景说明: 赋予 user01 用户对 default 名称空间拥有 Pod 的读取权限
1 | // 创建 role 角色,设定对应的规则 |
- 创建 rolebinding 角色绑定,将 user01 绑定至对应的 role 上
1 | // 命令方式 |
- 使用 user01 用户验证权限
1 | # kubectl get pod --context="user01@kubernetes" |
12.3.2 RBAC 场景-2
- 场景说明:赋予 user01 用户对所有名称空间拥有 Pod 的读取权限 (ClusterRole、ClusterRoleBinding)
1 | // 创建 clusterrole |
- 创建 clusterrolebinding,并绑定 user01 用户至对应的 clusterrole
1 | // 命令方式 |
- 使用 user01 用户验证权限
1 | # kubectl get pod --context="user01@kubernetes" |
12.3.3 RBAC 场景-3
- 场景说明: 赋予 user01 用户对 default 名称空间拥有管理员权限
- 系统内置了一个 ClusterRole: admin 的集群管理员,我们可以通过 rolebinding 引用 ClusterRole: admin 集群角色,该引用会造成用户仅对 rolebinding 所在的名称空间有管理员权限。(因为 rolebinding 仅能作用在名称空间范围内)
1 | // 删除此前的绑定,避免权限受到干扰 |
12.3.4 内置ClusterRole
- k8s 系统内置了一组默认的 ClusterRole 和 ClusterRoleBinding 资源预留给系统使用,其中大多数都以 system: 为前缀。还有一些不易 system: 为前缀的 ClusterRole 是面向用户设计的,比如:集群管理员角色 cluster-admin、admin、edit、view 掌握这些默认的内置角色资源有助于按需创建用户并分配相应的权限
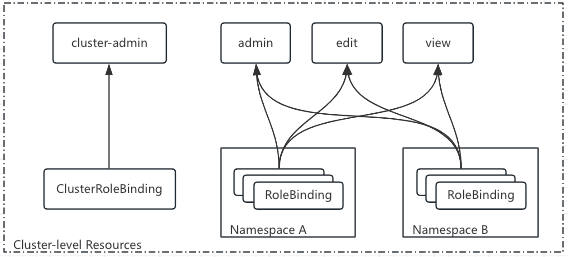
- Cluster-admin 分析:内置的 cluster-admin 资源拥有管理集群所有资源的权限,而内置的 cluster-admin 将该角色分配给了 system:master 组,这意味着所有加入该组的用户将自动具有集群的超级管理员权限
- 在使用 kubeadm 安装集群时,它自动创建配置文件 /etc/kubernetes/admin.conf 中定义的用户为 kubernetes-admin,而该用户使用数字证书, Subject 属性值为 /o=system:master。所以 API Server 会在成功验证该用户的身份之后将其识别为 system:master 用户组成员
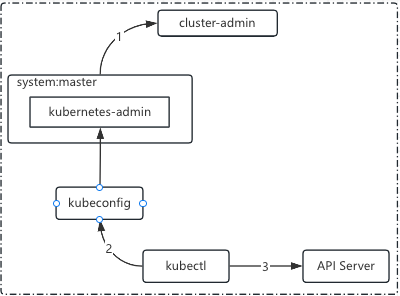
1 | // 分析过程如下: |
12.3.4.1 Cluster-admin 实践
- 创建一个 ops 用户,然后将该用户加入到 system:masters 组中,验证是否拥有集群管理员权限
1 | 1. 创建证书私有文件 |
13.0 准入控制
- APIServer 中准入控制器是以插件形式存在的,他们会拦截所有已完成认证的用户,且与资源创建、更新、删除操作相关的请求
- 通过 APIServer 启用的准入控制插件,然后强制实现定义的功能,比如:对象的语义验证、以及设置缺省字段的默认值等 k8s 通过 ResourceQuota 以及 LimitRange 准入控制器,可以为多租户或多项目的集群环境提供资源配额与限制
13.1 ResoucesQuta
资源配额:当系统存在多个用户或团队共享具有固定节点的 k8s 集群时,一般会根据不同团队创建不同的命名空间,但可能会出现某个应用将该命名空间的 CPU 或 内存耗尽的情况,无法保证其公平分配原则。可以通过 ResourceQuotas 资源配额来解决这个问题。ResourceQuota 主要是对每个命名空间的资源使用总量设定限制
- 它可以限制命名空间中某种类型对象的所创建的总数进行限制
- 也可以限制命名空间中 Pod 可以使用的 CPU 或 内存资源的总上线
场景-1:当用户在命名空间下创建资源(如:Pod、Service 等)时,k8s 的配额会跟踪集群的资源使用情况,以确保使用的资源用量不超过 ResourceQuota 中定义的资源限额。如果资源创建或更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN),并在消息中给出违反的信息描述
场景-2:如果命名空间下的计算资源(如 cpu 和 memory)的配额被启用,则用户必须为这些资源设定(requests)和(limit),否则配额系统将决绝 Pod 的创建。提示:可使用LimitRange 准入控制器来为没有设置计算资源的 Pod 设置默认值
配额策略示例:在具有 32GiB 内存和 16C 资源的集群中
- 允许 A 团队使用 20GiB 内存和 10C 的资源
- 允许 B 团队使用 10GiB 内存和 4C 的资源
- 预留 2GiB 内存和 2C 资源供将来分配
限制 test 命名空间使用 1C 和 1GiB 内存。允许 prod 命名空间使用任意数量,当集群容量小于各命名空间配额总和的情况下,可能存在资源竞争。资源竞争时,k8s 系统会遵循先到先得的原则。但不管是自愿竞争还是配额修改,都不会影响已经创建的资源使用对象
13.1.1 计算资源配额
- 用户可以对给定命名空间下的可被请求的 计算资源 总量进行限制
| 资源名称 | 描述 |
|---|---|
| requests.cpu | 所有非终止状态的 Pod,其 CPU 申请的总量不能超过该值 |
| requests.memory | 所有非终止状态的 Pod,其 内存 申请的总量不能超过该值 |
| limits.cpu | 所有非终止状态的 Pod,其 CPU 运行期间限制总量不能超过该值 |
| limits.memory | 所有非终止状态的 Pod,其 内存 运行期间限制总量不能超过该值 |
1 | // 示例 |
13.1.2 存储资源配额
- 用户可以对指定命名空间下的存储资源总量进行限制。此外,还可以根据相关的存储类(Storage Class)来限制存储资源的消耗
| 资源名称 | 描述 |
|---|---|
| requests.storage | 所有 PVC 存储资源的需求总量不能超过该值 |
| persistentvolumeclaims 3 | 在该命名空间中所允许的 PVC 总数量 |
| < storage-class-name >.storageclass.storage.k8s.io/requests.storage | 与 < storage-class-name > 相关的 PVC,存储请求的总和不能超过该值 |
| < storage-class-name >.storageclass.storage.k8s.io/persistentvolumeclaims | 与 < storage-class-name > 相关的 PVC,可以存在的 PVC 总数 |
1 | // 示例 |
13.1.3 对象数量配额
- 当使用 count/* 资源配额时,如果对象存在于服务器存储中,则会根据配额管理资源。这些类型的配额有助于防止存储资源耗尽。例如
- 用户可能想根据服务器的存储能力来对服务器中 secret 的数量进行配额限制,集群中存在过多的 secret 实际上回导致服务器和控制器无法启动
- 用户可以选择对 Job 进行配额管理,以防止配置不当的 CronJob 在某命名空间中创建太多 Job 而导致集群拒绝服务
| 资源名称 | 描述 |
|---|---|
| configmaps | 在该名称空间中允许存在的 ConfigMap 总数上限 |
| persistentvolumeclaims | 在该名称空间中允许存在的 PVC 的总数上限 |
| pods | 在该名称空间中允许存在的非终止状态的 Pod 总数上限。包含(Filed, Succeeded) |
| resourcequotas | 在该名称空间中允许存在的 ResourceQuota 总数上线 |
| services | 在该名称空间中允许存在的 service 总数上限 |
| rservies.loadbalancers | 在该名称空间中允许存在的 LoadBalancer 类型的 Service 总数上限 |
| services.nodeports | 在该名称空间中允许存在的 NodePort 类型的 Service 总数上限 |
| secrets | 在该名称空间中允许存在的 Secret 总数上限 |
13.1.4 计算资源配置
1 | 1. 创建一个名称空间,以便创建的资源和集群的其余资源相隔离 |
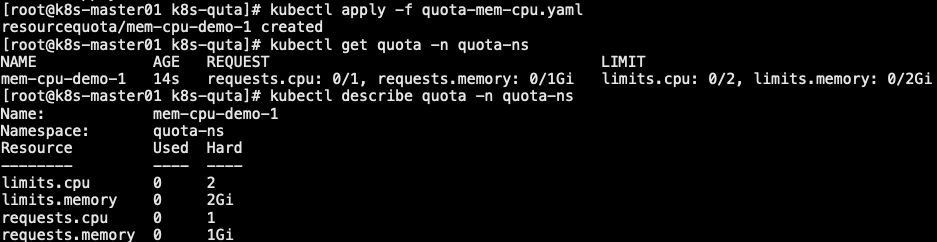
1 | 4. 创建第一个 Pod,申请 400m的 CPU,最大限制 800m。申请 600Mi 内存,最大限制 800Mi |
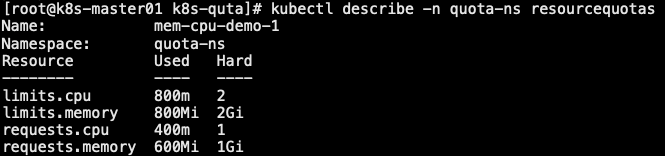
1 | 6. 创建第二个 Pod,申请 400m的 CPU,最大限制 800m。申请 700Mi 的内存,最大限制 1Gi |
13.1.5 存储资源配置
1 | 1. 创建资源清单文件 |
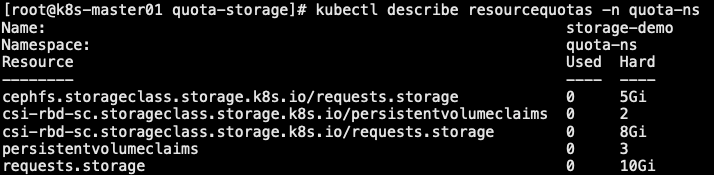
1 | 3. 创建第一个 PVC 申请,类型为 csi-rbd-sc,申请 5Gi |
1 | 4. 创建第二个 PVC 申请,先申请 3Gi,然后申请 2Gi,最后申请 1Gi |
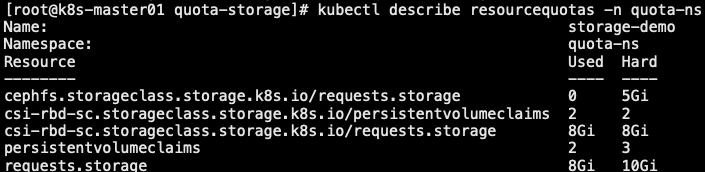
13.1.6 对象数量限制
- count/< resource >.< group >: 用于非核心(core)组的资源,比如 Ingress
- count/< resource >: 用于核心组的资源
1 | 1. 创建资源清单 |
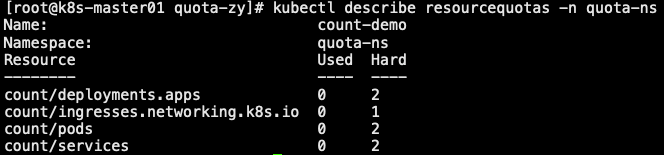
1 | 2. 创建一个 Deployment,副本数为 1,然后创建 Service 以及 Ingress 资源 |
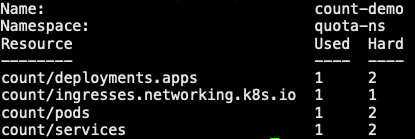
1 | 3. 创建一个 Deploy,Pod 副本数为 1,然后创建 Service 以及 Ingress 资源 |

13.2 LimitRange
- ResourceQuota 可以对名称空间资源总使用量进行限制。但可能会出现一个 Pod 申请的 CPU 或 内存设定非常大,从而将该名称空间中的可用资源被某个 Pod 所耗尽,所以可以通过 LimitRange 来限制名称空间中的每个 Pod 或每个 Container 的最大资源、最小资源。如果创建 Pod 没有给定对应的 resources 字段,还可以设定默认值进行自动填充
1 | // limitrange 示例 |
13.2.1 LimitRange 限制场景-1
- 为名称空间中未指定 Resources 字段的 Pod 资源,设定默认的 requests 和 limits
1 | 1. 创建 LimitRange 资源限制 |

1 | 3. 创建一个 Pod,并且在 Pod 中不申明任何的 cpu 与 内存 的 Requests 和 Limits |
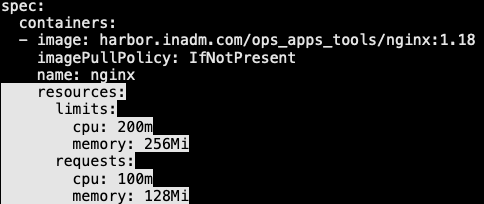
13.2.2 LimitRange 限制场景-2
- 创建容器时,如果指定了容器的 limits,而没有指定它的 requests 会怎么样 ?
1 | 1. 创建 Pod 的 yaml |
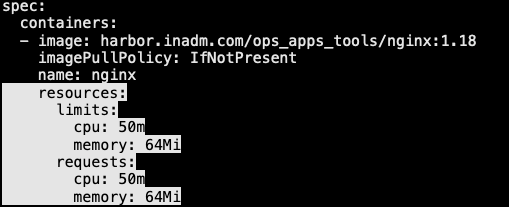
13.2.3 LimitRange 限制场景-3
- 声明容器的 CPU 和 内存 请求而不声明内存限制会怎样 ?
1 | 1. 创建 Pod 的 yaml |
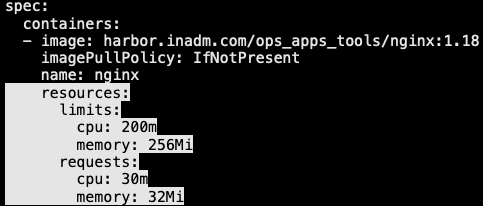
13.2.4 LimitRange 限制场景-4
- 通过 LimitRange,限制 Pod 创建时最小申请的资源(Request),以及 Pod 运行期间最大能使用的资源(Limits)
- 这样就可以将 ResourceQuota 和 LimitRange 结合起来,从而避免因某一个 Pod 超额申请资源而造成名称空间资源被耗尽
1 | 1. 创建 LimitRange |
13.2.5 LimitRange 限制存储
- 场景说明:
- 使用 ResourceQuota 限制名称空间中创建的 PVC 总容量,以及 PVC 的总数量
- 然后使用 LimitRange 限制每个 PVC 申请的最小容量和最大容量
1 | 1. 创建 ResourceQuotas 限制 PVC 的总容量以及创建的总数量 |


- 本文作者: [email protected]
- 本文链接: https://www.ink8s.com/2025/07/17/k8s-资源对象/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!