
- ceph 集群部署
- ceph deploy 安装
- RBD 块存储
- RGW 对象存储
- OSD 扩容
- RGW 高可用集群
- ceph 集群运维
- CRUSH Map 调整
- RBD 高级功能
- ceph 监控管理
1.0 ceph deploy 安装
1.1 安装方式
- 主流安装方式:
- cephadm
- ceph-deploy
- 手动安装
- Rook
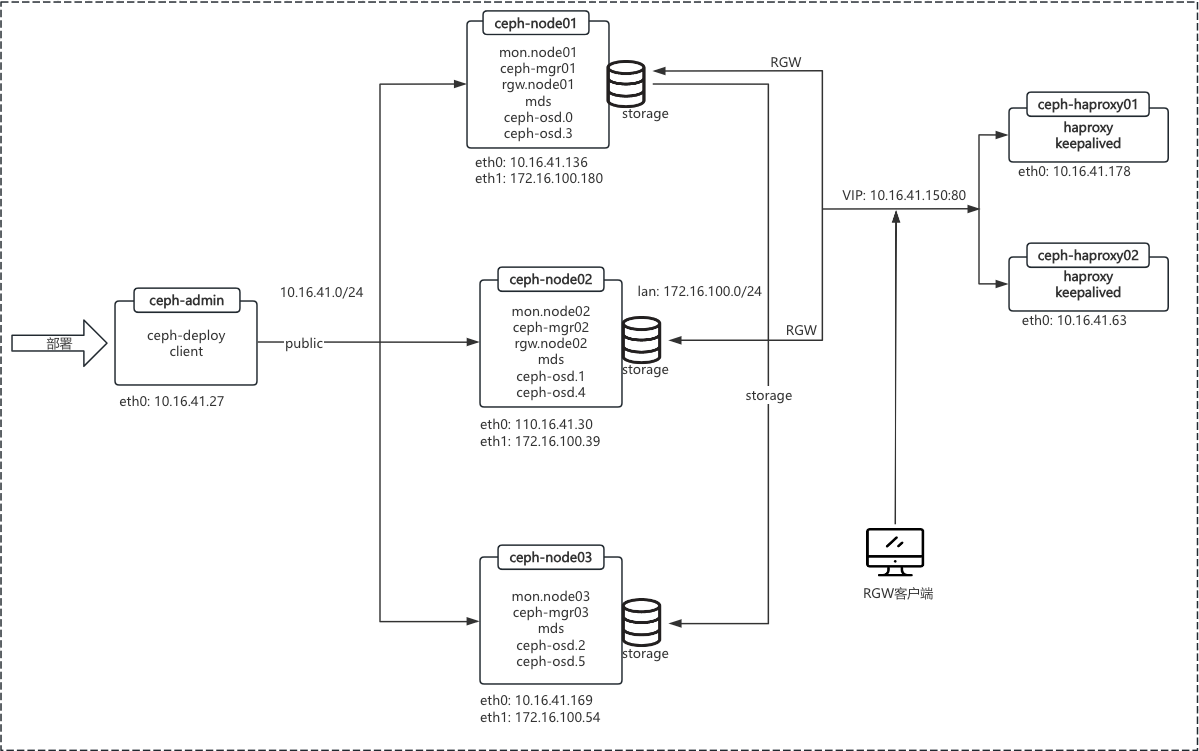
1.1.1 所需资源
| PUBLIC_IP | CLUSTER_IP | 主机名 | 配置 | 系统 | 服务 |
|---|---|---|---|---|---|
| 10.16.41.136 | 172.16.100.180 | ceph-node01 | 8C/16G/40G+(100G*2) | Centos7.9 | mon、ceph-mgr、mds、rgw |
| 10.16.41.30 | 172.16.100.39 | ceph-node02 | 8C/16G/40G+(100G*2) | Centos7.9 | mon、ceph-mgr、mds、rgw |
| 10.16.41.169 | 172.16.100.54 | ceph-node03 | 8C/16G/40G+(100G*2) | Centos7.9 | mon、ceph-mgr、mds |
| 10.16.41.27 | - | ceph-admin | 8C/16G/40G | Centos7.9 | ceph-admin、ceph-deploy、client、dashboard |
| 10.16.41.178 | - | ceph-haproxy01 | 8C/16G/40G | Centos7.9 | haproxy、keepalived |
| 10.16.41.63 | - | ceph-haproxy02 | 8C/16G/40G | Centos7.9 | haproxy、keepalived |
| vip: 10.16.41.150 |
1.1.2 集群拓扑
- public(公共): 客户端、前端
- cluster(集群): 专用、复制、后端
- 实际生产可根据需求确认是否部署 RGW
1.2 环境准备
1.2.1 主机名
- 6台 ceph 集群主机名和 hosts 全部规划和配置好
1 | # cat /etc/hosts |
1.2.1 keygen
- 在 ceph-admin 主机上配置 ssh-keygen 认证
1 | [root@ceph-admin ~]# ssh-keygen |
1.2.1 时间同步
- ceph 集群对时间精度要求非常高
1 | # timedatectl set-timezone Asia/Shanghai |
1.2.1 yum 源
- 阿里源: https://mirrors.aliyun.com/ceph/
- 中科大源: https://mirrors.ustc.edu.cn/ceph/
- 官方源: https://download.ceph.com/
1 | # cat /etc/yum.repos.d/ceph.repo |

1.3 ceph-deploy 安装
- 其它节点无需安装
1 | [root@ceph-admin ~]# yum -y install python-setuptools ceph-deploy |
1.4 monitor 节点部署
- 双网卡配置参考: https://docs.ceph.com/en/quincy/rados/configuration/network-config-ref/
- 部署: https://docs.ceph.com/en/nautilus/start/quick-ceph-deploy/
- 基础环境准备完成后,就可以正式安装 ceph 集群了,先安装 monitor 节点
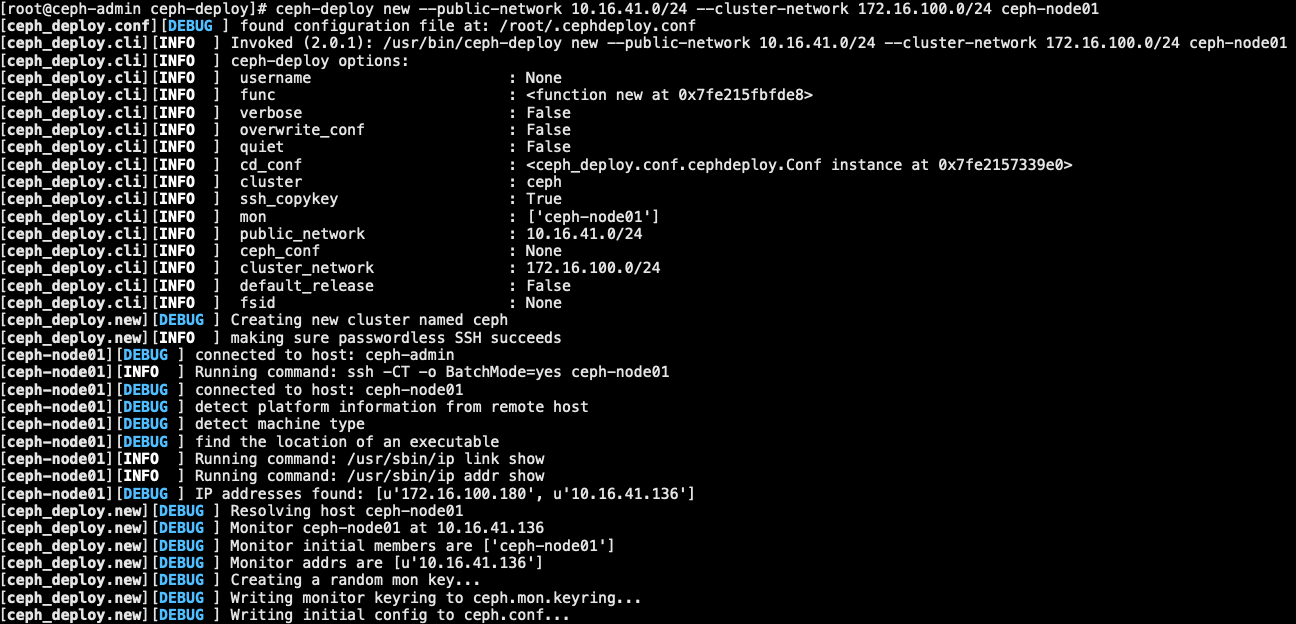
1.4.1 创建集群
1 | [root@ceph-admin ~]# mkdir -p /data/ceph-deploy |
1.4.2 ceph 软件包安装
- 采用手动方式安装;每个 node 节点都安装
1 | [root@ceph-node01 ~]# yum -y install ceph ceph-mon ceph-mgr ceph-radosgw ceph-mds |
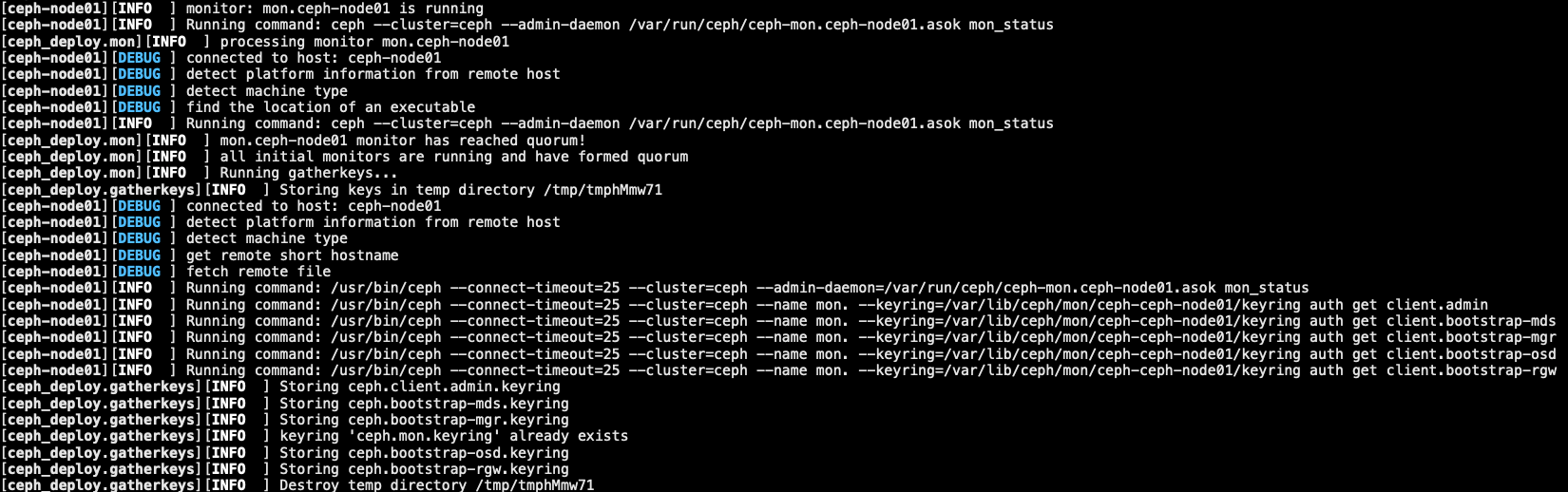
1.4.3 初始化 monitor
1 | [root@ceph-admin ceph-deploy]# ceph-deploy mon create-initial |
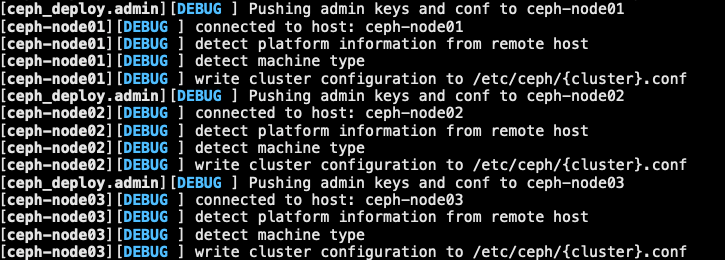
1.4.4 推送配置文件
- 将配置文件和管理秘钥推送到管理节点和 ceph 节点,以便可以使用 CLI, ceph 而无需 ceph.client.admin.keyring 在每次执行命令时指定 monitor 地址
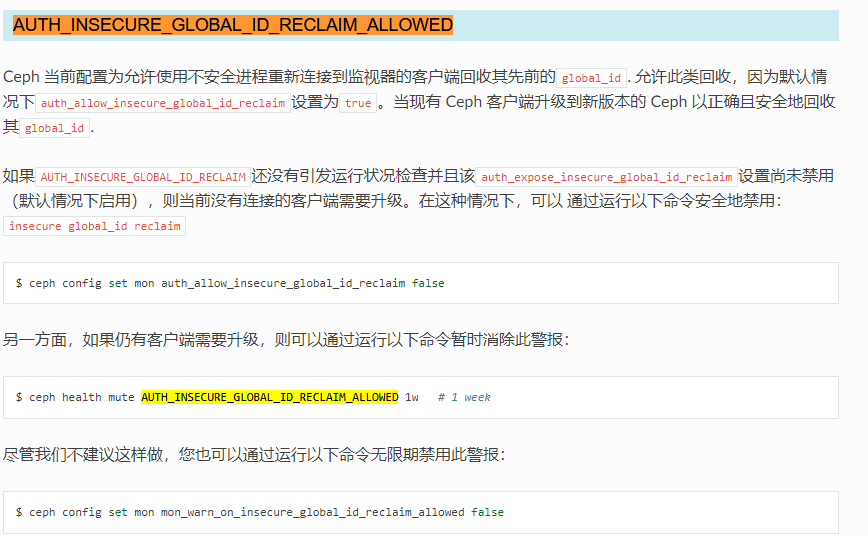
- 报错解决办法.官方网站
1 | [root@ceph-admin ceph-deploy]# ceph-deploy admin ceph-node01 ceph-node02 ceph-node03 |
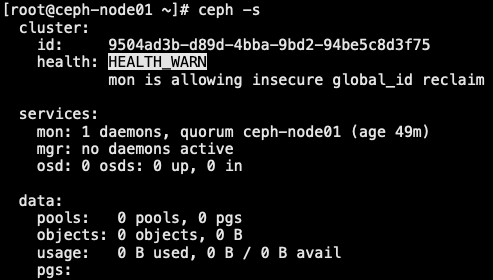
1.4.5 管理器守护进程
- 主要是用来监控用途
1 | [root@ceph-admin ceph-deploy]# ceph-deploy mgr create ceph-node01 |
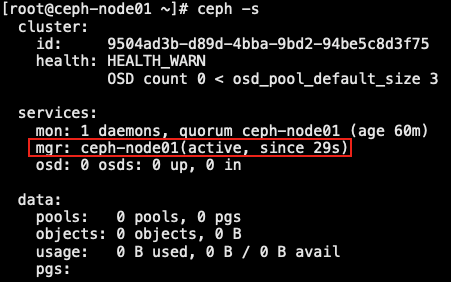
1.4.5 部署 OSD 节点
- 确认有相应的存储磁盘存在
1 | [root@ceph-admin ceph-deploy]# ceph-deploy osd create --data /dev/sdb ceph-node01 |
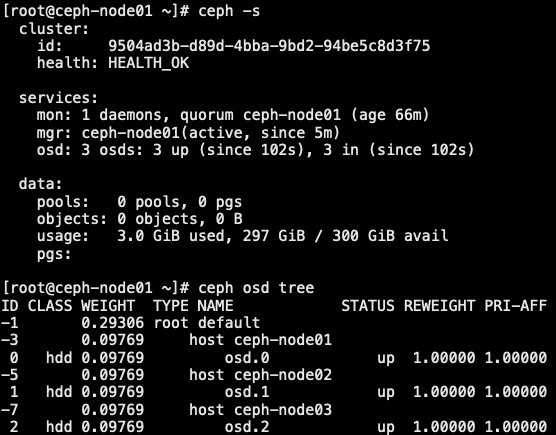
1.5 扩展 mon 与 mgr
- 一旦集群启动并运行,下一步就是扩展集群。将 ceph 元数据服务器添加到 ceph-node01。然后添加 ceph monitor 和 ceph manager ceph-node02 和 ceph-node03 提高可靠性和可用性
- 一个 ceph 存储集群至少需要一个 ceph monitor 和 ceph manager 才能运行。为了实现高可用性,ceph 存储集群通常运行多个 ceph monitor,这样单个 ceph monitor 的故障就不会导致 ceph 存储集群瘫痪。ceph 使用 paxos 算法,即基数才能形成仲裁
1.5.1 扩展 monitor
1 | [root@ceph-admin ceph-deploy]# ceph-deploy mon add ceph-node02 --address 10.16.41.30 |

1.5.2 添加管理器
- ceph manager 守护进程以 主动/备用 模式运行。部署额外的管理器守护进程可确保如果一个守护程序或主机发生故障,另外一个守护程序或主机可以接管不会中断服务
1 | [root@ceph-admin ceph-deploy]# ceph-deploy mgr create ceph-node02 ceph-node03 |
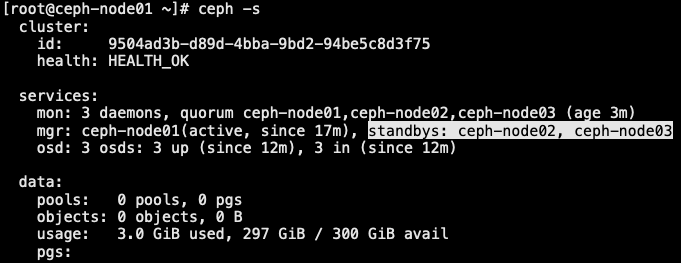
2.0 RBD 块存储
- ceph 可以同时提供对象存储 RADOSGW、块存储RBD、文件存储 Ceph FS。RBD 即 RADOS Block Device 的简称,RBD 块存储是最稳定且最常用的存储类型。RBD 块设备类似磁盘可以被挂载。RBD 块设备具有快照、多副本、克隆和一致性等特性,数据条带的方式在 Ceph 集群的多个 OSD 中。
- CEPH 存储

2.1 创建资源池 Pool
- 创建资源池.官方网站
- pg_num 因目前无法自动计算,以下是一些常用的值
- 小于 5 个 OSD 设置 pg_num 为 128
- 5 ~ 10 个 OSD 设置 pg_num 为 512
- 10 ~ 50 OSD 设置 pg_num 为 1024
- 如果超过 50 个 OSD,需要了解和权衡如何 pg_num 自行计算价值,pgcalc 工具
- 随着 OSD 数量增加,选择正确的 pg_num 值变得更加重要,因为它对集群的行为及出现问题时数据的持久性 (即灾难性时间导致数据丢失的概率) 有很大影响
1 | [root@ceph-node01 ~]# ceph osd lspools # 查看块设备池命令 |
2.2 RBD 创建和映射
2.2.1 创建、删除、查看
1 | // 在 ceph-client 节点上创建块设备镜像 |
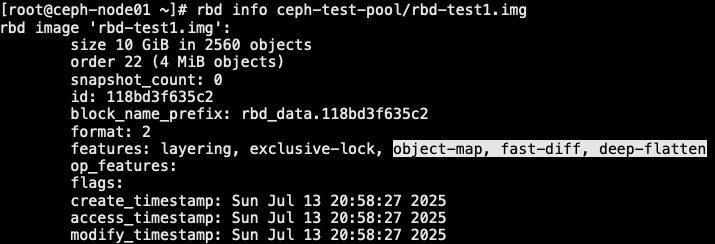
2.2.2 禁用特性
- 去掉它不支持的相关特性 [object-map, fast-diff, deep-flatten]
1 | // 将镜像映射到块;一般情况下块设备是给到虚拟机去使用的,这里实验,则直接将挂到内核上测试验证 |
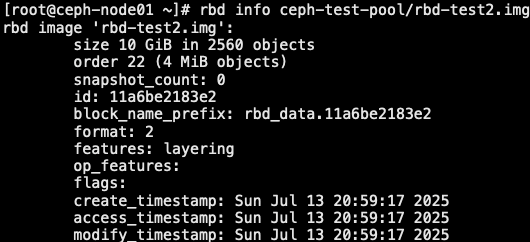
2.2.3 挂载
1 | [root@ceph-node01 ~]# rbd map ceph-test-pool/rbd-test2.img # 镜像挂载到 "/dev/rbd0" 设备 |

2.2.4 使用
1 | [root@ceph-node01 ~]# fdisk -l /dev/rbd0 # 同本地磁盘一样 |

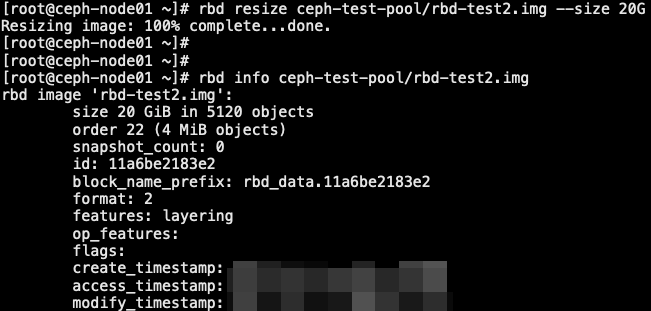
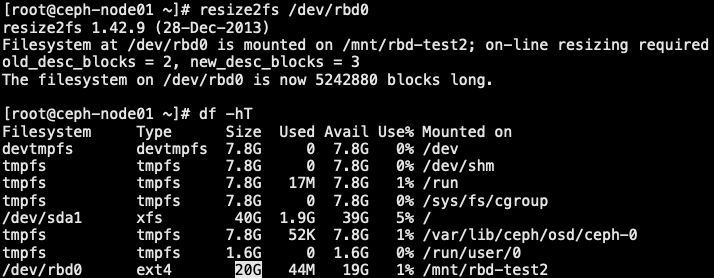
2.3 RBD 块存储扩容
- 磁盘扩容一般分三个层面: RBD 底层扩容、磁盘 MBR或者GPT 扩容、文件系统扩容
1 | // 基于 rbd-test2.img 这块盘进行扩容 |
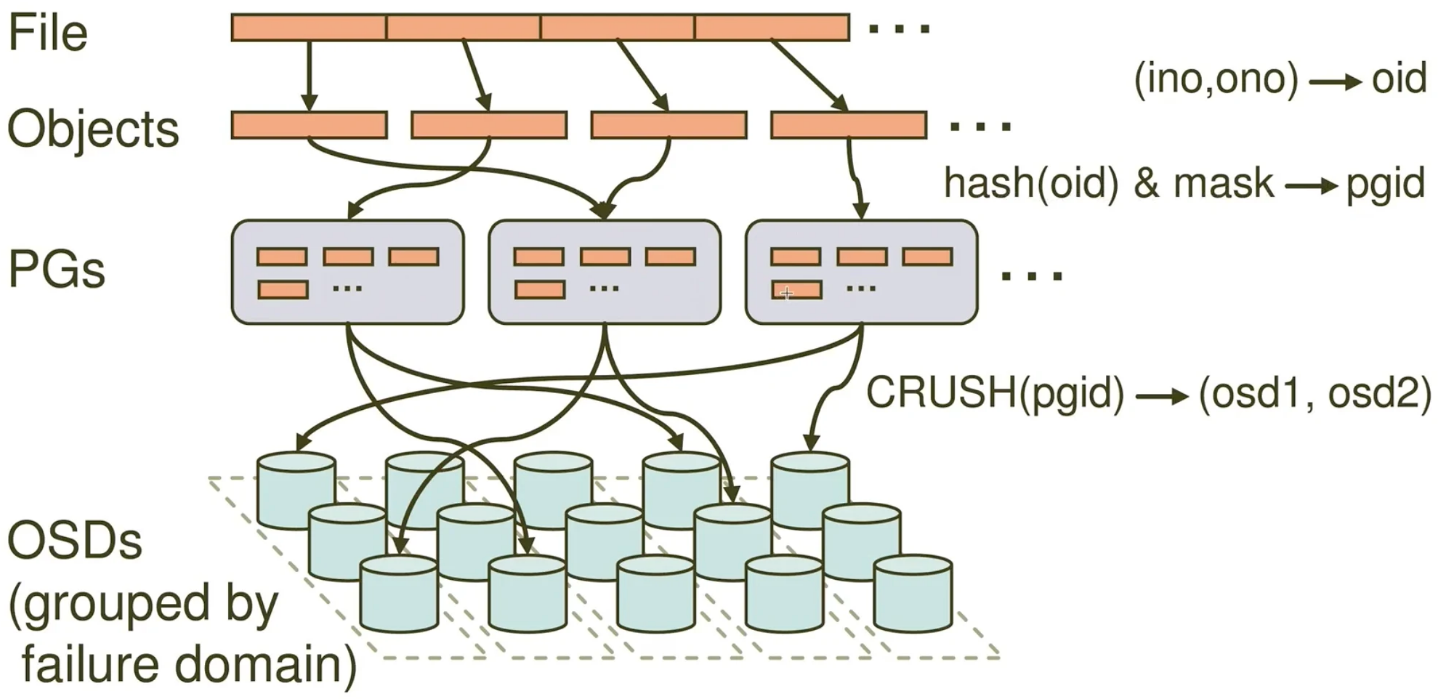
2.4 RBD 数据写入流程
- 一个文件最终会切割成多个 objects
- 每个 objects 是 4M 大小
- objects 再存储到 PG 上,会经过一次 hash 的运算,再取掩码 mask,得到它落在哪个 pg 上
- 然后 pg 再通过 CRUSH 算法,最终找到对应的 OSD 上
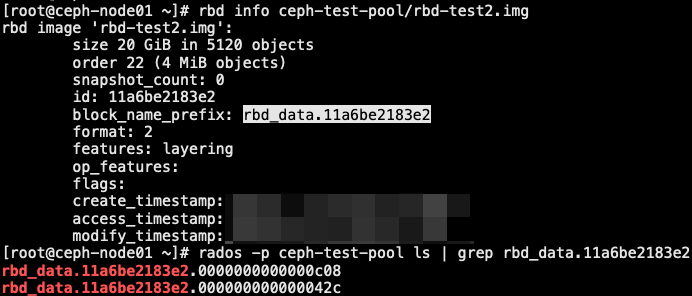
1 | 1. objects |

3.0 RGW 对象存储
- 通过对象存储,将数据存储为对象,每个对象除了包含数据,还包含数据自身的元数据
- 对象通过 Object ID 来检索,无法通过普通文件系统操作来直接访问对象,只能通过 API 来访问,或者第三方客户端(实际也是对API的封装)
- 对象存储中的对象不整理到目录中,而是存储在扁平的命名空间中,Amazon S3 将这个扁平命名空间成为 bucket

3.1 RGW 网关架构

3.2 部署 RGW 存储网关
1 | // 确认 radosgw 包已经安装 |

3.3 修改 RGW 默认端口
- 7480 Civetweb 默认在端口上运行。要更改默认端口 (例如,更改为 80),请修改管理服务器工作目录中的 ceph 配置文件。添加标题为 [client.rgw.
]的部分,替换 为 ceph 对象官网节点的短节点名称 (即: hostname -s) - 端口修改.官方网站
3.3.1 修改配置文件
1 | // 修改 ceph-deploy 文件中的 ceph.conf,确保配置的唯一性 |
3.3.2 push 配置到集群节点
1 | [root@ceph-admin ceph-deploy]# ceph-deploy --overwrite-conf config push ceph-node01 ceph-node02 ceph-node03 |
3.3.3 配置生效
- 重启配置、检查端口是否生效
1 | [root@ceph-node01 ~]# systemctl restart ceph-radosgw.target |
3.4 RGW 之 S3 接口使用
- 兼容 S3 风格
- swift 风格
3.4.1 兼容 S3 风格
3.4.1.1 创建用户
1 | // 要使用 REST 接口,首先为 S3 接口创建初始 ceph 对象网关用户。然后,为 swift 界面创建一个子用户。然后需要验证创建的用户是否能够访问网关。 |
3.4.1.2 CMD 管理对象存储
- 基于运维人员通过命令 cmd 来管理
1 | [root@ceph-node01 ~]# s3cmd --configure |
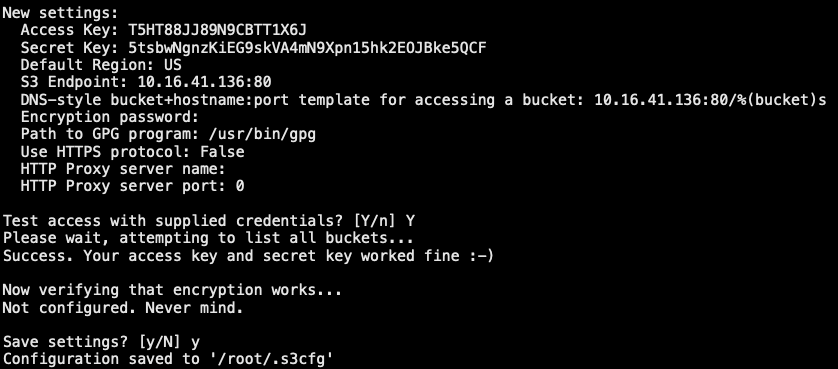
3.4.1.32 s3cmd 使用方法
1 | // 命令使用方法 |
3.4.1.4 s3cmd 上传对象
1 | [root@ceph-node01 ~]# s3cmd put /etc/fstab s3://s3cmd-test1/fstab-file |

3.4.1.5 s3cmd 上传目录
1 | [root@ceph-node01 ~]# s3cmd put /etc/ s3://s3cmd-test1/etc/ --recursive # 空目录无法上传 |
3.4.1.6 s3cmd 下载、删除
1 | [root@ceph-node01 ~]# s3cmd get s3://s3cmd-test1/etc/exports exports # 下载到本地目录 |
3.4.1.7 数据存储位置信息
1 | [root@ceph-node01 ~]# ceph osd lspools # 当向 bucket 传入数据后,就会多一个 pool |
3.4.2 swift 风格 API 接口
3.4.2.1 用户创建
- 可以通过命令行客户端验证快速访问 swift。该命令将提供有关可用命令行选择的更多信息 man swift
1 | // 创建一个 swift 用户需要在 s3 用户基础之上创建 swift 用户 |
3.4.2.2 依赖安装
- swift 客户端相关依赖安装
1 | [root@ceph-admin ~]# yum -y install python-setuptools python-pip python36 |
3.4.2.3 命令使用
1 | [root@ceph-admin ~]# swift post swift-bucket-demo # 创建 bucket |
3.4.3 删除块设备镜像
- 删除 rbd-test2.img 块设备
1 | // 删除块设备和调整 pg、pgp 大小,确保在部署 MDS 时,不会出现 PG 报错 |
3.5 MDS 集群部署
- Create a Ceph file system.官方网站
- Ceph File System.官方网站
- ceph file system 是与 POSIX 标准兼容的文件系统,能够提供对 ceph 存储集群上的文件访问。 ceph 需要至少一个源数据服务器(metadata server - MDS) daemon-mds(ceph-mds)运行,MDS管理者与存储在 cephFS 上的文件相关的元数据,并且协调着对 ceph 存储系统的访问
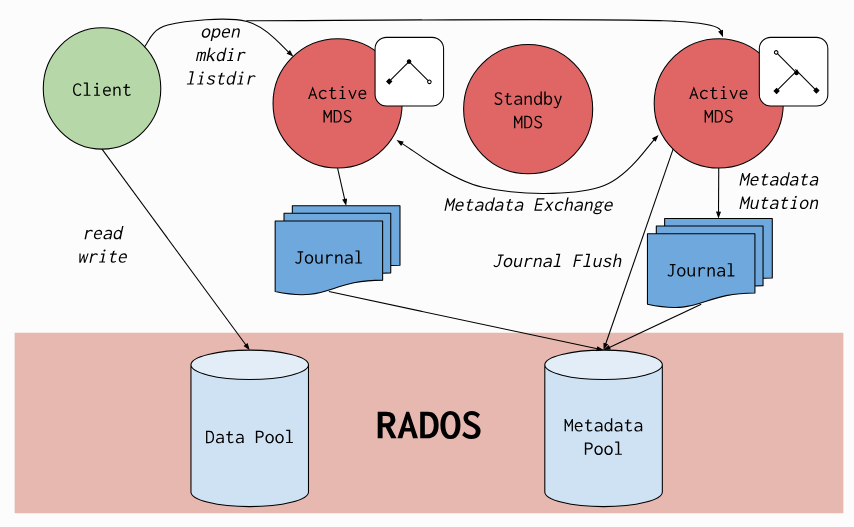
3.5.1 安装部署 MDS 集群
1 | // 要使用 CephFS, 至少就需要一个 metadata server 进程。可以手动创建一个 MDS, 也可以使用 ceph-deploy 或者 ceph-ansible 来部署 MDS |
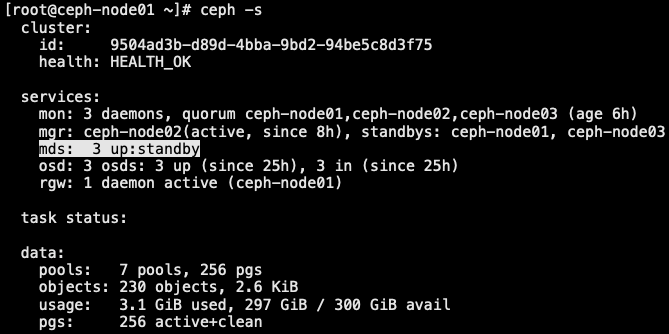
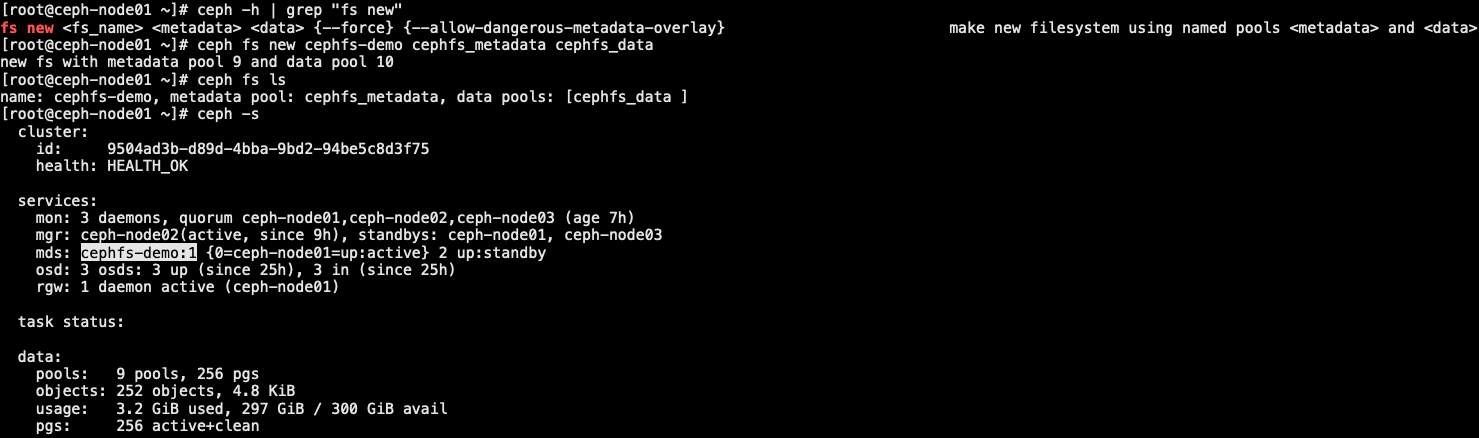
3.5.2 创建 cephFS 文件系统
- cephFS 需要2个 pools-cephfs-data 和 cephfs-metadata,分别存储文件数据和文件元数据
1 | // cephFS 需要2个 pools-cephfs-data 和 cephfs-metadata,分别存储文件数据和文件元数据 |
1 | // osd 比较少,pg 也相对需要少一点 |
3.5.3 cephFS 内核挂载
- 以 kernel client 形式挂载 cephFS,可以手动用 mount 命令挂载 cephFS 或者通过 /etc/fstab 自动挂载 cephFS
- 挂载有2中方式:
- 手动挂载
- sudo mount -t ceph mon1:6789,mon2:6789,mon3:6789/ /cephfs -o name=cephfs,secretfile=/etc/ceph/cephfs.secret
- stat -f /cephfs# 验证
- 自动挂载
- mkdir -p /cephfs
- echo “mon1:6789,mon2:6789,mon3:6789:/ /cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0” | tee -a /etc/fstab
- mount -a
- 手动挂载
3.5.3.1 kernel driver
- 将 CephFS 挂载为内核驱动程序
1 | [root@ceph-node01 ~]# mkdir /mnt/cephfs |
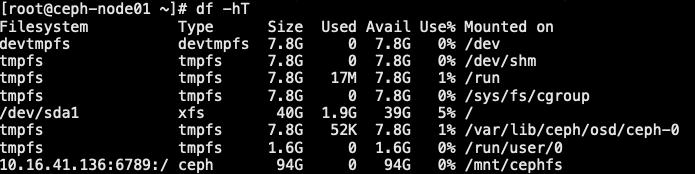
1 | [root@ceph-node01 ~]# cat /etc/fstab |
1 | [root@ceph-node01 ~]# mkdir /opt/test-mnt |

1 | [root@ceph-node01 ~]# echo "test cephfs /mnt/cephfs" > /mnt/cephfs/cephfs.txt |
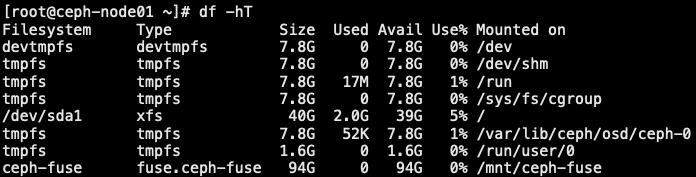
3.5.3.2 ceph-fuse 用户态挂载
- 以 FUSE client 形式挂载,同样的,可以手动通过 ceph-fuse 挂载或者通过向 /etc/fstab 添加挂载项自动挂载
- 参考文档
1 | [root@ceph-admin ~]# yum -y install ceph-fuse |
4.0 OSD 扩容
- 横向扩容(scale out): 简单的理解,就是增加节点,通过增加节点来达到增加容量的目的
- 纵向库容(scale up):通过增加现有节点的硬盘(OSD)来达到增加容量的目的
4.1 纵向扩容
1 | [root@ceph-admin ceph-deploy]# ceph-deploy disk list ceph-node01 # 列出磁盘 |
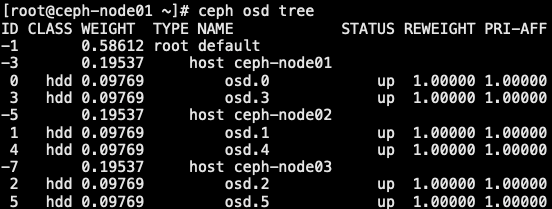
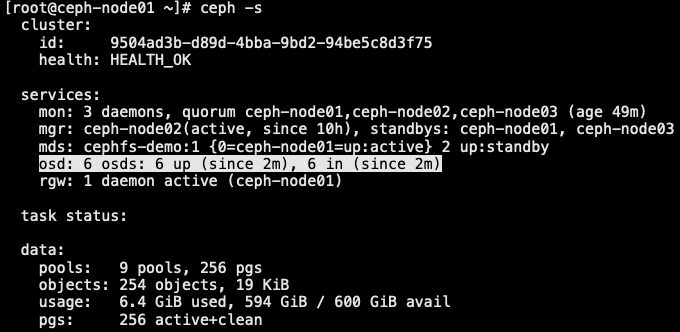
4.2 数据 rebalancing 重分布
- 扩容过程中的注意事项和数据的重分布(rebalancing [重新平衡])
- 一次性添加大量的 OSD 对集群性能影响会很大。建议少量的或者逐台添加方式以减小其性能影响。最小化的对业务造成不必要的影响
- 随着集群资源的不断增长,ceph 集群的空间会存在不够用的情况,因此需要对集群进行扩容,扩容通常包含两种:
- 横向库容: 增加机器
- 纵向扩容: 在单个节点上添加更多的 OSD 存储,以满足数据增长的需求
- 添加 OSD 的时候由于集群的状态 (cluster map) 已发生改变,因此会涉及到数据的重分布(rebalancing),即 pool 的 PGs 数量是固定的,需要将 PGs 数平均分摊到多个 OSD 节点上
4.3 验证 rebalancing 过程
1 | [root@ceph-node01 ~]# dd if=/dev/zero of=rebalancing-file.img bs=1M count=8192 |
4.4 验证 rebalancing 过程
- 当在做 rebalance 的时候,每个 osd 都会按照 osd_max_backfiles 指定数量的线程来同步,如果该数值比较大,同步会比较快,但是会影响部分性能
- 另外数据同步时,是走的 cluster_network,而客户端连接是用的 public_network,生产环境建议这两个网络用万兆网络,减少网络传输的影响
- 同样,为了避免业务繁忙时候 rebalance 带来的性能影响,可以对 rebalance 进行关闭;当业务比较小的时候,再打开
1 | [root@ceph-node01 ~]# ceph --admin-daemon /var/run/ceph/ceph-mon.ceph-node01.asok config show | grep max_backfills |
4.5 数据一致性检查
- ceph 作为分布式存储系统,在可用性和一致性方面有极高的要求
- ceph 区别与其他分布式数据库等产品,更多的是作为云计算基础设施提供服务
- 作为维护数据一致性和清洁度的一部分,Ceph OSD 还可以清理归置组内的对象。也就是说,Ceph OSD 可以将一个置放组中的对象元数据与其他 OSD 中存储的置放组中的副本进行比较。清理(通常每天执行)可以捕获 OSD 错误或文件系统错误。OSD 还可以通过逐位比较对象中的数据来执行更深入的清理。深度清理(通常每周执行一次)可以发现磁盘上在轻度清理中不明显的坏扇区
- 数据一致性检测也可以手动做,一般都是针对 PG 来做
1 | [root@ceph-node01 ~]# ceph -h | grep scrub |
5.0 RGW 高可用集群
- 无状态化服务,可以采用 keepalived+haproxy方式
5.1 扩展 RGW 集群
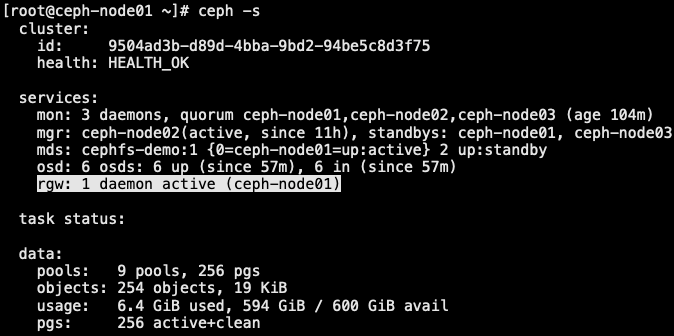
1 | [root@ceph-admin ceph-deploy]# ceph-deploy rgw create ceph-node02 # 让 ceph-node02 也成为 rgw |
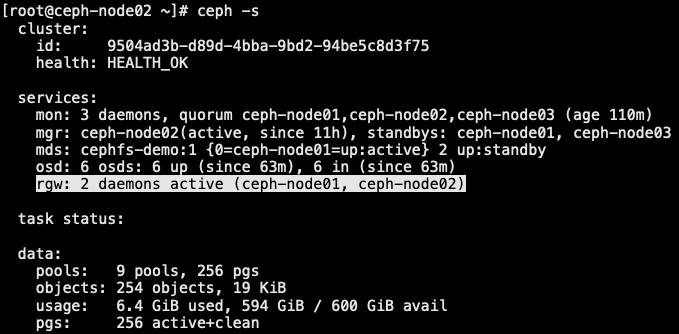
5.2 RGW 高可用负载均衡
5.2.1 keepalived 安装配置
5.2.1.1 主机 ceph-haproxy01 配置
1 | [root@ceph-haproxy01 ~]# yum -y install wget gcc make tar openssl openssl-devel libnl libnl-devel libnfnetlink-devel psmisc |
1 | [root@ceph-haproxy01 keepalived-2.0.10]# cd /data/apps/keepalived/etc/keepalived/ |
1 | [root@ceph-haproxy01 keepalived]# chmod +x /opt/check.sh |

5.2.1.2 主机 ceph-haproxy02 配置
1 | [root@ceph-haproxy02 ~]# yum -y install wget gcc make tar openssl openssl-devel libnl libnl-devel libnfnetlink-devel psmisc |
1 | [root@ceph-haproxy02 keepalived-2.0.10]# cd /data/apps/keepalived/etc/keepalived/ |
1 | [root@ceph-haproxy02 keepalived]# chmod +x /opt/check.sh |
5.2.2 配置 haproxy
- 2台 haproxy 安装一样
1 | # yum -y install gcc readline-devel openssl-devel systemd-devel socat |
1 | # cat /usr/lib/systemd/system/haproxy.service |
5.2.2.1 主机 haproxy01
1 | [root@ceph-haproxy01 ~]# mkdir -p /data/apps/haproxy/conf.d |
1 | [root@ceph-haproxy01 ~]# cat /data/apps/haproxy/conf.d/haproxy-stats.cfg |
1 | [root@ceph-haproxy01 ~]# cat /data/apps/haproxy/conf.d/ceph.cfg |
5.2.2.2 主机 haproxy02
1 | [root@ceph-haproxy02 ~]# mkdir -p /data/apps/haproxy/conf.d |
1 | [root@ceph-haproxy02 ~]# cat /data/apps/haproxy/conf.d/haproxy-stats.cfg |
1 | [root@ceph-haproxy02 ~]# cat /data/apps/haproxy/conf.d/ceph.cfg |
- 浏览器访问: http://10.16.41.150:9999/haproxy-status
admin:ink8s.com
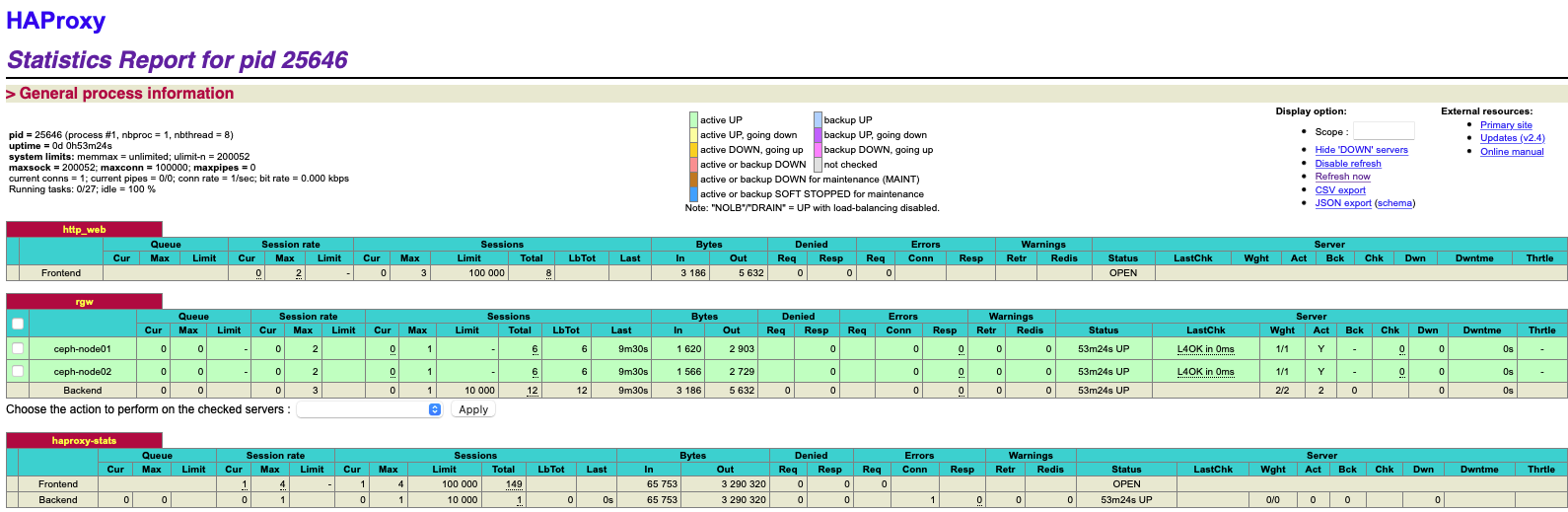
5.2.3 修改客户端指向
1 | [root@ceph-node01 ~]# vim /root/.s3cfg |
6.0 ceph 集群运维
7.0 CRUSH Map 调整
8.0 RBD 高级功能
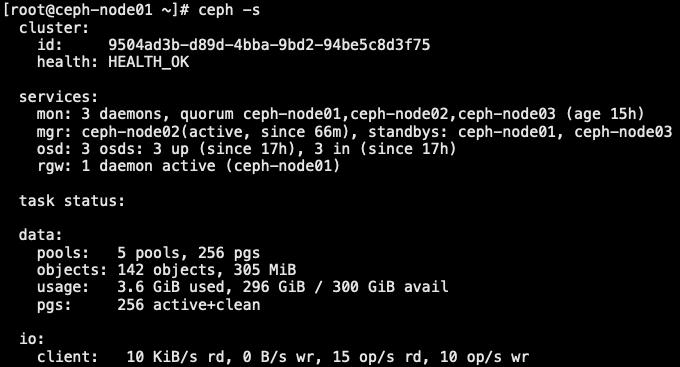
9.0 ceph 监控管理

- 本文作者: [email protected]
- 本文链接: https://www.ink8s.com/2025/07/12/ceph-deploy-部署/
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!